1.1 Kubernetes 介绍¶
Kubernetes是Google公司在2014年6月开源的一个容器集群管理系统,使用Go语言开发,也叫K8S(k8s 这个缩写是因为k和s之间有八个字符的关系)。Kubernetes这个名字源于希腊语,意为“舵手”或“飞行员”。Kubernetes的目标是让部署容器化的应用 简单并且高效,提供应用部署,维护,规划,更新。Kubernetes一个核心的特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行,让用户能够方便的部署自己的应用。
Kubernetes官网地址如下:https://kubernetes.io/,中文官网地址如下:https://kubernetes.io/zh-cn/

企业中应用程序的部署经历了传统部署时代、虚拟化部署时代、容器化部署时代,尤其是今天容器化部署应用在企业中应用非常广泛,Kubernetes作为容器编排管理工具也越来越重要。
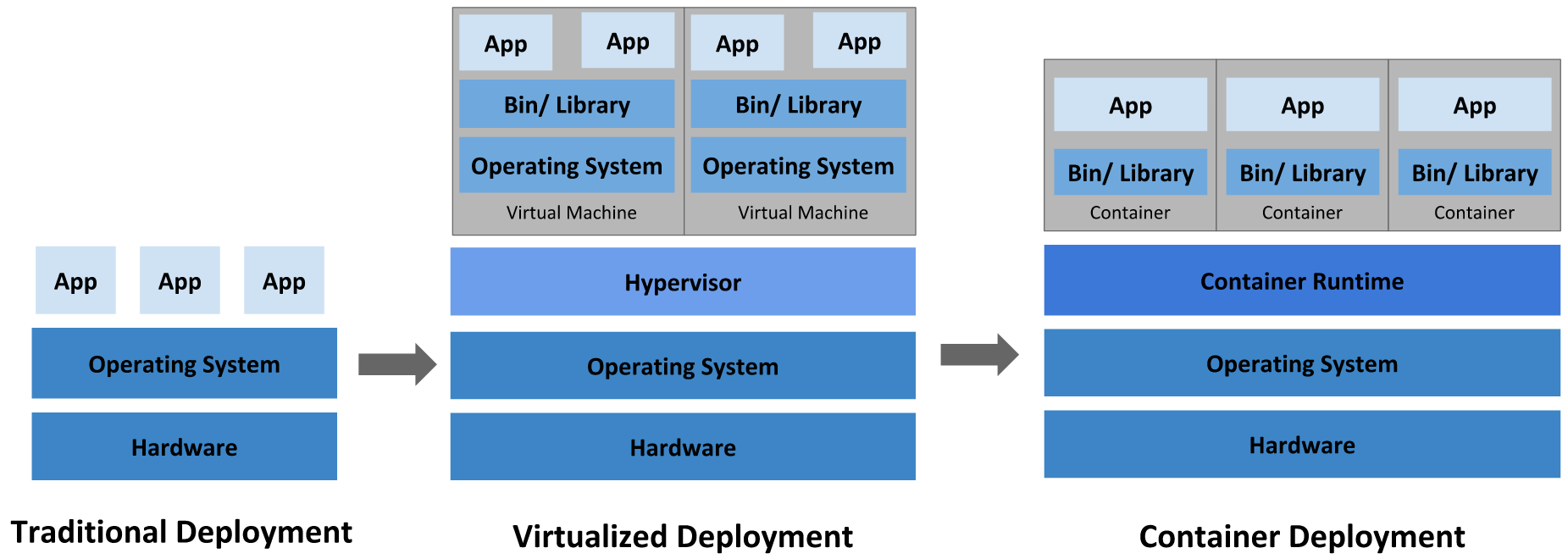
1.1.1 传统部署时代¶
早期,各个公司是在物理服务器上运行应用程序。由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。例如,如果在同一台物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。一种解决方案是将每个应用程序都运行在不同的物理服务器上,但是当某个应用资源利用率不高时,服务器上剩余资源无法被分配给其他应用,而且维护许多物理服务器的成本很高。
物理服务器部署应用痛点如下:
- 物理服务器环境部署人力成本大,特别是在自动化手段不足的情况下,依靠人肉运维的方式解决。
- 当物理服务器出现宕机后,服务器重启时间过长,短则1-2分钟,长则3-5分钟,有背于服务器在线时长达到99.999999999%标准的要求。
- 物理服务器在应用程序运行期间硬件出现故障,解决较麻烦。
- 物理服务器计算资源不能有效调度使用,无法发挥其充足资源的优势。
- 物理服务器环境部署浪费时间,没有自动化运维手段,时间是成倍增加的。
- 在物理服务器上进行应用程序配置变更,需要停止之前部署重新实施部署。
1.1.2 虚拟化部署时代¶
由于以上原因,虚拟化技术被引入了,虚拟化技术允许你在单个物理服务器的CPU上运行多台虚拟机(VM)。虚拟化能使应用程序在不同VM之间被彼此隔离,且能提供一定程度的安全性,因为一个应用程序的信息不能被另一应用程序随意访问。每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序,因此具有更高的可扩缩性,以及降低硬件成本等等的好处。通过虚拟化,你可以将一组物理资源呈现为可丢弃的虚拟机集群。
虚拟机部署应用优点:
- 虚拟机较物理服务器轻量,可借助虚拟机模板实现虚拟机快捷生成及应用。
- 虚拟机中部署应用与物理服务器一样可控性强,且当虚拟机出现故障时,可直接使用新的虚拟机代替。
- 在物理服务器中使用虚拟机可高效使用物理服务器的资源。
- 虚拟机与物理服务器一样可达到良好的应用程序运行环境的隔离。
- 当部署应用程序的虚拟机出现宕机时,可以快速启动,时间通常可达秒级,10秒或20秒即可启动,应用程序可以继续提供服务。
- 在虚拟机中部署应用,容易扩容及缩容实现、应用程序迁移方便。
虚拟机部署应用缺点:
- 虚拟机管理软件本身占用物理服务器计算资源较多,例如:VMware Workstation Pro就会占用物理服务器大量资源。
- 虚拟机底层硬件消耗物理服务器资源较大,例如:虚拟机操作系统硬盘,会直接占用大量物理服务器硬盘空间。
- 相较于容器技术,虚拟机启动时间过长,容器启动可按毫秒级计算。
- 虚拟机对物理服务器硬件资源调用添加了调链条,存在浪费时间的现象,所以虚拟机性能弱于物理服务器。
- 由于应用程序是直接部署在虚拟机硬盘上,应用程序迁移时,需要连同虚拟机硬盘中的操作系统一同迁移,会导致迁移文件过大,浪费更多的存储空间及时间消耗过长。
1.1.3 容器化部署时代¶
容器类似于VM,但具备更宽松的隔离特性,使容器之间可以共享操作系统(OS),因此,容器比起VM被认为是更轻量级的。容器化技术中常用的就是Docker容器引擎技术,让开发者可以打包应用以及依赖到一个可移植的镜像中,然后发布到任何平台,其与VM类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。由于它们与基础架构分离,因此可以跨云和OS发行版本进行移植。
基于容器化技术部署应用优点 :
- 不需要为容器安装操作系统,可以节约大量时间。
- 不需要通过手动的方式在容器中部署应用程序的运行环境,直接部署应用就可以了。
- 不需要管理容器网络,以自动调用的方式访问容器中应用提供的服务。
- 方便分享与构建应用容器,一次构建,到处运行,可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 等地方运行。
- 毫秒级启动。
- 资源隔离与资源高效应用。应用程序被分解成较小的独立部分,并且可以动态部署和管理,而不是在一台大型单机上整体运行,可以在一台物理机上高密度的部署容器。
虽然使用容器有以上各种优点,但是 使用容器相比于物理机容器可控性不强 ,例如:对容器的访问,总想按物理服务器或虚拟机的方式去管理它,其实容器与物理服务器、虚拟机管理方式上有着本质的区别的,最好不要管理。
1.1.4 为什么需要Kubernetes¶
一般一个容器中部署运行一个服务,一般不会在一个容器运行多个服务,这样会造成容器镜像复杂度的提高,违背了容器初衷。企业中一个复杂的架构往往需要很多个应用,这就需要运行多个容器,并且需要保证这些容器之间有关联和依赖,那么如何保证各个容器自动部署、容器之间服务发现、容器故障后重新拉起正常运行,这就需要容器编排工具。
Kubernetes就是一个容器编排工具,可以实现容器集群的自动化部署、自动扩展、维护等功能,可以基于Docker技术的基础上,为容器化应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高大规模容器集群管理的便捷性。
**Kubernetes**优点如下:
- 服务发现和负载均衡
Kubernetes可以使用DNS名称或自己的IP地址来曝露容器。如果进入容器的流量很大,Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排
Kubernetes允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
- 自动部署和回滚
你可以使用Kubernetes描述已部署容器的所需状态,它可以以受控的速率将实际状态更改为期望状态。例如,可以通过Kubernetes来为你部署创建新容器、删除现有容器并将它们的所有资源用于新容器。
- 自动完成装箱计算
在Kubernetes集群上运行容器化的任务时,Kubernetes可以根据运行每个容器指定的多少CPU和内存(RAM)将这些容器按实际情况调度到Kubernetes集群各个节点上,以最佳方式利用集群资源。
- 自我修复
Kubernetes将重新启动失败的容器、替换容器、杀死不响应的容器,并且在准备好服务之前不将其通告给客户端。
- 密钥与配置管理
Kubernetes允许你存储和管理敏感信息,例如密码、OAuth令牌和ssh密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
1.2 Kubernetes集群架构及组件¶
一个Kubernetes集群至少有一个主控制平面节点(Control Plane)和一台或者多台工作节点(Node)组成,控制面板和工作节点实例可以是物理设备或云中的实例。Kubernetes 架构如下:

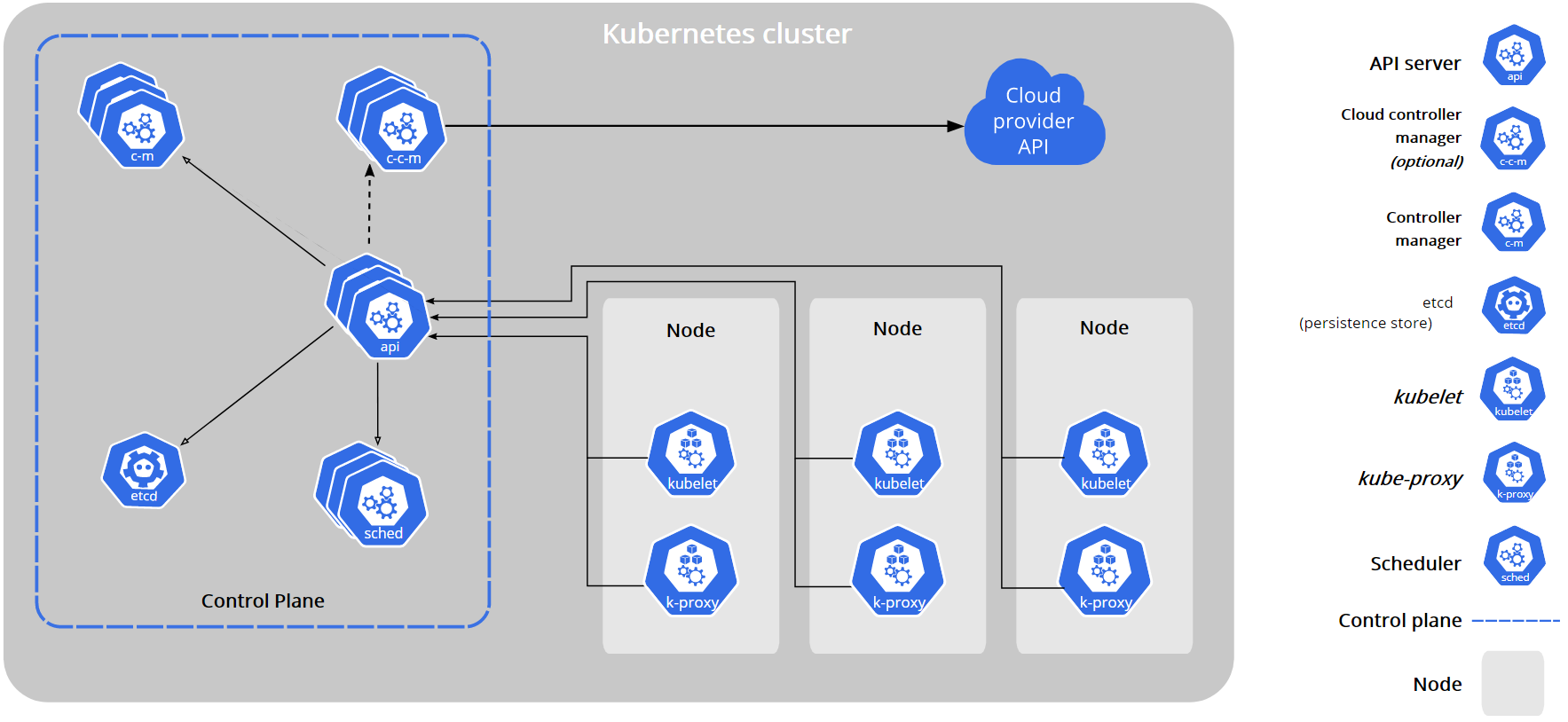
1.2.1 Kubernetes 控制平面(Contorl Plane)¶
Kubernetes控制平面也称为主节点(Master Node),其管理集群中的工作节点(Worker Node)和Pod,在生产环境中,Master节点可以运行在多台节点实例上形成主备,提供Kubernetes集群的容错和高可用性。我们可以通过CLI或者UI页面中向Master节点输入参数控制Kubernetes集群。
Master节点是Kubernetes集群的管理中心,包含很多组件,这些组件管理Kubernetes集群各个方面,例如集群组件通信、工作负载调度和集群状态持久化。这些组件可以在集群内任意节点运行,但是为了方便会在一台实例上运行Master所有组件,并且不会在此实例上运行用户容器。
Kubernetes Master主节点包含组件如下:
- kube-apiserver:
用于暴露kubernetes API,任何的资源请求/调用操作都是通过kube-apiserver提供的接口进行。例如:通过REST/kubectl 操作Kubernetes集群调用的就是Kube-apiserver。
- etcd:
etcd是一个一致的、高度可用的键值存储库,是kubernetes提供默认的存储系统,用于存储Kubernetes集群的状态和配置数据。
- kube-scheduler:
scheduler负责监视新创建、未指定运行节点的Pods并选择节点来让Pod在上面运行。如果没有合适的节点,则将Pod处于挂起的状态直到出现一个健康的Node节点。
- kube-controller-manager:
controller-manager 负责运行Kubernetes中的Controller控制器,这些Controller控制器包括:
- 节点控制器(Node Controller):负责在节点出现故障时进行通知和响应。
- 任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成。
- 端点分片控制器(EndpointSlice controller):填充端点分片(EndpointSlice)对象(以提供 Service 和 Pod 之间的链接)。
- 服务账号控制器(ServiceAccount controller):为新的命名空间创建默认的服务账号(ServiceAccount)。
- cloud-controller-manager
云控制器管理器(Cloud Controller Manager)嵌入了特定于云平台的控制逻辑,允许你将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。cloud-controller-manager 仅运行特定于云平台的控制器。 因此如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的集群不需要有云控制器管理器。
1.2.2 Kubernetes Node节点¶
Kubernetes Node节点又称为工作节点(Worker Node),一个Kubernetes集群至少需要一个工作节点,但通常很多,工作节点也包含很多组件,用于运行以及维护Pod及service等信息, 管理volume(CVI)和网络(CNI)。在Kubernetes集群中可以动态的添加和删除节点来扩展和缩减集群。
工作节点Node上的组件如下:
- Kubelet:
Kubelet会在集群中每个Worker节点上运行,负责维护容器(Containers)的生命周期(创建pod,销毁pod),确保Pod处于运行状态且健康。同时也负责Volume(CVI)和网络(CNI)的管理。Kubelet不会管理不是由Kubernetes创建的容器。
- kube-proxy:
Kube-proxy是集群中每个Worker节点上运行的网络代理,管理IP转换和路由,确保每个Pod获得唯一的IP地址,维护网络规则,这些网络规则会允许从集群内部或外部的网络会话与Pod进行网络通信。
- container Runtime:
容器运行时(Container Runtime)负责运行容器的软件,为了运行容器每个Worker节点都有一个Container Runtime引擎,负责镜像管理以及Pod和容器的启动停止。
1.3 Kubernetes 核心概念¶
Kubernetes中有非常多的核心概念,下面主要介绍Kubernetes集群中常见的一些概念。
1.3.1 Pod¶
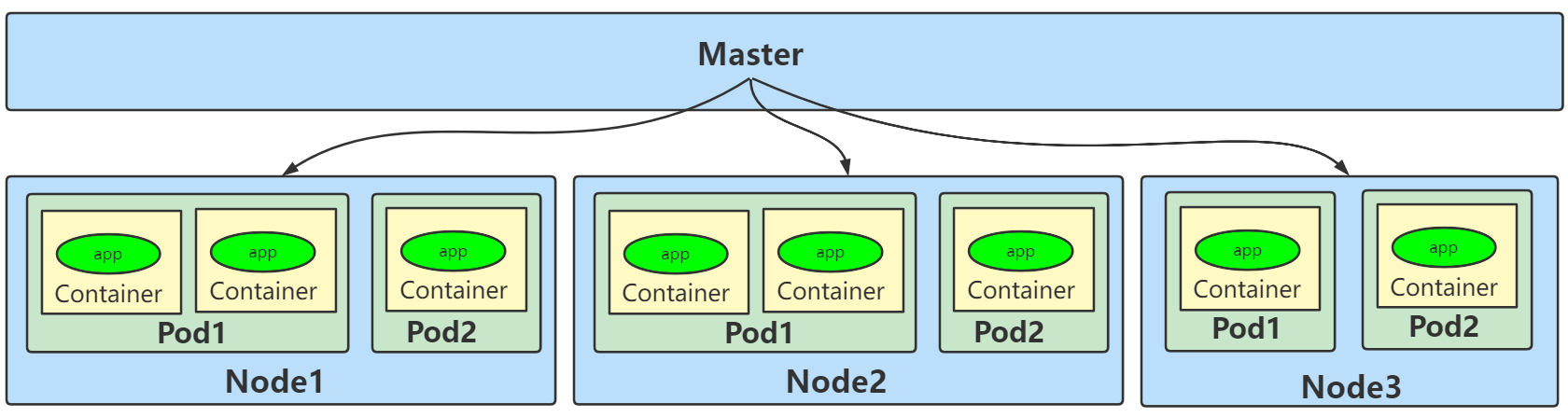
Pod是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元,是Kubernetes调度的基本单位,Pod设计的理念是每个Pod都有一个唯一的IP。Pod就像豌豆荚一样,其中包含着一组(一个或多个)容器,这些容器共享存储、网络、文件系统以及怎样运行这些容器的声明。


Node&Pod&Container&应用程序关系如下图所示:

1.3.2 Label¶
Label是附着到object上(例如Pod)的键值对。可以在创建object的时候指定,也可以在object创建后随时指定。Labels的值对系统本身并没有什么含义,只是对用户才有意义。
一个Label是一个key=value的键值对,其中key与value由用户自己指定。Label可以附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去,Label通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
我们可以通过指定的资源对象捆绑一个或多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置、部署等管理工作。例如:部署不同版本的应用到不同的环境中;或者监控和分析应用(日志记录、监控、告警)等。
一些常用abel示例如下所示:
- 版本标签:"release" : "stable" , "release" : "canary"...
- 环境标签:"environment" : "dev" , "environment" : "production"
- 架构标签:"tier" : "frontend" , "tier" : "backend" , "tier" : "middleware"
- 分区标签:"partition" : "customerA" , "partition" : "customerB"...
- 质量管控标签:"track" : "daily" , "track" : "weekly"
Label相当于我们熟悉的“标签”,给某个资源对象定义一个Label,就相当于给它打了一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制。
1.3.3 NameSpace¶
Namespace 命名空间是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或者用户组。常见的pod、service、replicaSet和deployment等都是属于某一个namespace的(默认是default),而node, persistentVolumes等则不属于任何namespace。
当删除一个命名空间时会自动删除所有属于该namespace的资源,default和kube-system命名空间不可删除。
1.3.4 Controller控制器¶
在 Kubernetes 中,Contorller用于管理和运行Pod的对象,控制器通过监控集群的公共状态,并致力于将当前状态转变为期望的状态。一个Controller控制器至少追踪一种类型的 Kubernetes 资源。这些对象有一个代表期望状态的spec字段。该资源的控制器负责确保其当前状态接近期望状态。
不同类型的控制器实现的控制方式不一样,以下介绍常见的几种类型的控制器。
1.3.4.1 deployments控制器¶
deployments控制器用来部署无状态应用。基于容器部署的应用一般分为两种,无状态应用和有状态应用。
- 无状态应用:认为Pod都一样,没有顺序要求,随意进行扩展和伸缩。例如:nginx,请求本身包含了响应端为响应这一请求所@需的全部信息。每一个请求都像首次执行一样,不会依赖之前的数据进行响应,不需要持久化数据,无状态应用的多个实例之间互不依赖,可以无序的部署、删除或伸缩。
- 有状态应用:每个pod都是独立运行,有唯一的网络表示符,持久化存储,有序。例如:mysql主从,主机名称固定,而且其扩容以及升级等操作也是按顺序进行。有状态应用前后请求有关联与依赖,需要持久化数据,有状态应运用的多个实例之间有依赖,不能相互替换。
在Kubernetes中,一般情况下我们不需要手动创建Pod实例,而是采用更高一层的抽象或定义来管理Pod,针对无状态类型的应用,Kubernetes使用Deloyment的Controller对象与之对应,其典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
1.3.4.2 ReplicaSet控制器¶
通过改变Pod副本数量实现Pod的扩容和缩容,一般Deployment里包含并使用了ReplicaSet。对于ReplicaSet而言,它希望pod保持预期数目、持久运行下去,除非用户明确删除,否则这些对象一直存在,它们针对的是耐久性任务,如web服务等。
1.3.4.3 statefulSet控制器¶
Deployments和ReplicaSets是为无状态服务设计的,StatefulSet则是为了有状态服务而设计,其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC(PersistentVolumeClaim,持久存储卷声明)来实现。
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现。
注意从写法上来看statefulSet与deployment几乎一致,就是类型不一样。
1.3.4.4 DaemonSet控制器¶
DaemonSet保证在每个Node上都运行一个相同Pod实例,常用来部署一些集群的日志、监控或者其他系统管理应用。DaemonSet使用注意以下几点:
- 当节点加入到Kubernetes集群中,pod会被(DaemonSet)调度到该节点上运行。
- 当节点从Kubernetes集群中被移除,被DaemonSet调度的pod会被移除。
- 如果删除一个Daemonset,所有跟这个DaemonSet相关的pods都会被删除。
- 如果一个DaemonSet的Pod被杀死、停止、或者崩溃,那么DaemonSet将会重新创建一个新的副本在这台计算节点上。
- DaemonSet一般应用于日志收集、监控采集、分布式存储守护进程等。
1.3.4.5 Job控制器¶
ReplicaSet针对的是耐久性任务,对于非耐久性任务,比如压缩文件,任务完成后,pod需要结束运行,不需要pod继续保持在系统中,这个时候就要用到Job。Job负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
1.3.4.6 Cronjob控制器¶
Cronjob类似于Linux系统的crontab,在指定的时间周期运行相关的任务。
1.3.5 Service¶
使用kubernetes集群运行工作负载时,由于Pod经常处于用后即焚状态,Pod经常被重新生成,因此Pod对应的IP地址也会经常变化,导致无法直接访问Pod提供的服务,Kubernetes中使用了Service来解决这一问题,即在Pod前面使用Service对Pod进行代理,无论Pod怎样变化 ,只要有Label,就可以让Service能够联系上Pod,把PodIP地址添加到Service对应的端点列表(Endpoints)实现对Pod IP跟踪,进而实现通过Service访问Pod目的。
Service有以下几个注意点:
- 通过service为pod客户端提供访问pod方法,即可客户端访问pod入口
- 通过标签动态感知pod IP地址变化等
- 防止pod失联
- 定义访问pod访问策略
- 通过label-selector相关联
- 通过Service实现Pod的负载均衡
Service 有如下四种类型:
- ClusterIP:默认,分配一个集群内部可以访问的虚拟IP。
- NodePort:在每个Node上分配一个端口作为外部访问入口。nodePort端口范围为:30000-32767
- LoadBalancer:工作在特定的Cloud Provider上,例如Google Cloud,AWS,OpenStack。
- ExternalName:表示把集群外部的服务引入到集群内部中来,即实现了集群内部pod和集群外部的服务进行通信,适用于外部服务使用域名的方式,缺点是不能指定端口。
1.3.6 Volume 存储卷¶
默认情况下容器的数据是非持久化的,容器消亡以后数据也会跟着丢失。Docker容器提供了Volume机制以便将数据持久化存储。Kubernetes提供了更强大的Volume机制和插件,解决了容器数据持久化以及容器间共享数据的问题。
Kubernetes存储卷的生命周期与Pod绑定,容器挂掉后Kubelet再次重启容器时,Volume的数据依然还在,Pod删除时,Volume才会清理。数据是否丢失取决于具体的Volume类型,比如emptyDir的数据会丢失,而PV的数据则不会丢。
目前Kubernetes主要支持以下Volume类型:
- emptyDir:Pod存在,emptyDir就会存在,容器挂掉不会引起emptyDir目录下的数据丢失,但是pod被删除或者迁移,emptyDir也会被删除。
- hostPath:hostPath允许挂载Node上的文件系统到Pod里面去。
- NFS(Network File System):网络文件系统,Kubernetes中通过简单地配置就可以挂载NFS到Pod中,而NFS中的数据是可以永久保存的,同时NFS支持同时写操作。
- glusterfs:同NFS一样是一种网络文件系统,Kubernetes可以将glusterfs挂载到Pod中,并进行永久保存。
- cephfs:一种分布式网络文件系统,可以挂载到Pod中,并进行永久保存。
- subpath:Pod的多个容器使用同一个Volume时,会经常用到。
- secret:密钥管理,可以将敏感信息进行加密之后保存并挂载到Pod中。
- persistentVolumeClaim:用于将持久化存储(PersistentVolume)挂载到Pod中。
除了以上几种Volume类型,Kubernetes还支持很多类型的Volume,详细可以参考:https://kubernetes.io/docs/concepts/storage/
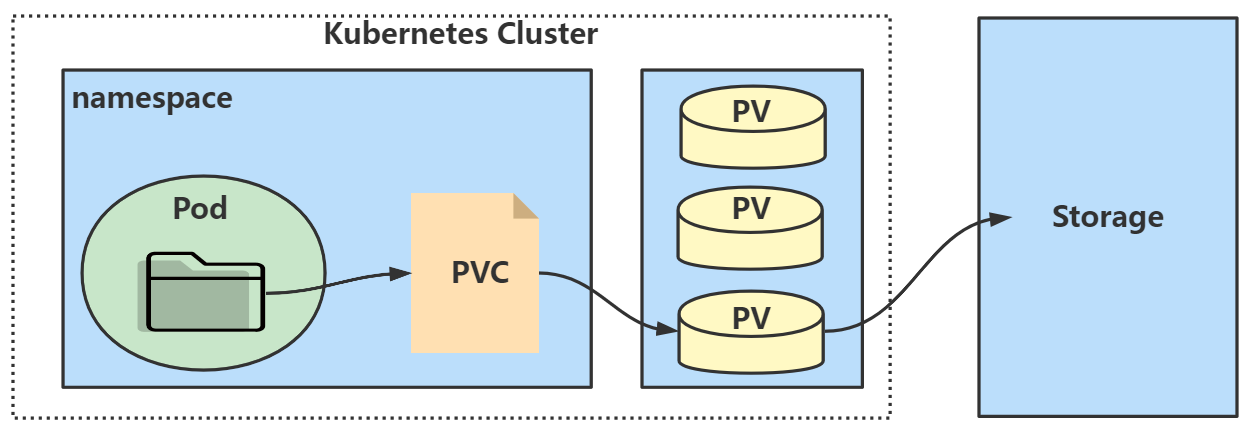
1.3.7 PersistentVolume(PV) 持久化存储卷¶
kubernetes存储卷的分类太丰富了,每种类型都要写相应的接口与参数才行,这就让维护与管理难度加大,PersistentVolume(PV)是集群之中的一块网络存储,跟 Node 一样,也是集群的资源。PV是配置好的一段存储(可以是任意类型的存储卷),将网络存储共享出来,配置定义成PV。PersistentVolume (PV)和PersistentVolumeClaim (PVC)提供了方便的持久化卷, PV提供网络存储资源,而PVC请求存储资源并将其挂载到Pod中,通过PVC用户不需要关心具体的volume实现细节,只需要关心使用需求。
1.3.8 ConfigMap¶
ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件,实现对容器中应用的配置管理,可以把ConfigMap看作是一个挂载到pod中的存储卷。ConfigMap跟secret很类似,但它可以更方便地处理不包含敏感信息的明文字符串。
1.3.9 Secret¶
Sercert-密钥解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。
1.3.10 ServiceAccount¶
Service account是为了方便Pod里面的进程调用Kubernetes API或其他外部服务而设计的。Service Account为服务提供了一种方便的认证机制,但它不关心授权的问题。可以配合RBAC(Role Based Access Control)来为Service Account鉴权,通过定义Role、RoleBinding、ClusterRole、ClusterRoleBinding来对sa进行授权。
1.4 Kubernetes 集群搭建环境准备¶
这里使用kubeadm部署工具来进行部署Kubernetes。Kubeadm是为创建Kubernetes集群提供最佳实践并能够“快速路径”构建kubernetes集群的工具。它能够帮助我们执行必要的操作,以获得最小可行的、安全的集群,并以用户友好的方式运行。
1.4.1 节点划分¶
kubernetes 集群搭建节点分布:
| 节点IP | 节点名称 | Master | Worker |
|---|---|---|---|
| 192.168.179.4 | node1 | ★ | |
| 192.168.179.5 | node2 | ★ | |
| 192.168.179.6 | node3 | ★ | |
| 192.168.179.7 | node4 | ||
| 192.168.179.8 | node5 |
1.4.2 升级内核¶
升级操作系统内核,升级到6.06内核版本。这里所有主机均操作,包括node4,node5节点。
#导入elrepo gpg key
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#安装elrepo YUM源仓库
yum -y install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
#安装kernel-ml版本,ml为长期稳定版本,lt为长期维护版本
yum --enablerepo="elrepo-kernel" -y install kernel-ml.x86_64
#设置grub2默认引导为0
grub2-set-default 0
#重新生成grub2引导文件
grub2-mkconfig -o /boot/grub2/grub.cfg
#更新后,需要重启,使用升级的内核生效。
reboot
#重启后,需要验证内核是否为更新对应的版本
uname -r
6.0.6-1.el7.elrepo.x86_64
1.4.3 配置内核转发及网桥过滤¶
在所有K8S主机配置。添加网桥过滤及内核转发配置文件:
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
加载br_netfilter模块:
#加载br_netfilter模块
modprobe br_netfilter
#查看是否加载
lsmod | grep br_netfilter
加载网桥过滤及内核转发配置文件:
sysctl -p /etc/sysctl.d/k8s.conf
1.4.4 安装ipset及ipvsadm¶
所有主机均需要操作。主要用于实现service转发。
#安装ipset及ipvsadm
yum -y install ipset ipvsadm
配置ipvsadm模块加载方式,添加需要加载的模块
vim /etc/sysconfig/modules/ipvs.modules
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
授权、运行、检查是否加载
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack
1.4.5 关闭SWAP分区¶
修改完成后需要重启操作系统,如不重启,可临时关闭,命令为swapoff -a。永远关闭swap分区,需要重启操作系统。
#永久关闭swap分区 ,在 /etc/fstab中注释掉下面一行
vim /etc/fstab
#/dev/mapper/centos-swap swap swap defaults 0 0
#重启机器
reboot
1.4.6 安装docker¶
所有集群主机均需操作。
获取docker repo文件
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
查看docker可以安装的版本:
yum list docker-ce.x86_64 --showduplicates | sort -r
安装docker:这里指定docker版本为20.10.9版本
yum -y install docker-ce-20.10.9-3.el7
如果安装过程中报错:
Error: Package: 3:docker-ce-20.10.9-3.el7.x86_64 (docker-ce-stable)
Requires: container-selinux >= 2:2.74
Error: Package: docker-ce-rootless-extras-20.10.9-3.el7.x86_64 (docker-ce-stable)
Requires: fuse-overlayfs >= 0.7
Error: Package: docker-ce-rootless-extras-20.10.9-3.el7.x86_64 (docker-ce-stable)
Requires: slirp4netns >= 0.4
Error: Package: containerd.io-1.4.9-3.1.el7.x86_64 (docker-ce-stable)
缺少一些依赖,解决方式:在/etc/yum.repos.d/docker-ce.repo开头追加如下内容:
[centos-extras]
name=Centos extras - $basearch
baseurl=http://mirror.centos.org/centos/7/extras/x86_64
enabled=1
gpgcheck=0
然后执行安装命令:
yum -y install slirp4netns fuse-overlayfs container-selinux
执行完以上之后,再次执行yum -y install docker-ce-20.10.9-3.el7安装docker即可。
设置docker 开机启动,并启动docker:
systemctl enable docker
systemctl start docker
查看docker版本
docker version
修改cgroup方式,并重启docker。
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
#重启docker
systemctl restart docker
1.5 Kubernetes 集群搭建¶
1.5.1 软件版本¶
这里安装Kubernetes版本为1.25.3,在所有主机(node1,node2,node3)安装kubeadm,kubelet,kubectl。
kubeadm:初始化集群、管理集群等。
kubelet:用于接收api-server指令,对pod生命周期进行管理。
kubectl:集群应用命令行管理工具。
1.5.2 准备阿里yum源¶
每台k8s节点vim /etc/yum.repos.d/k8s.repo,写入以下内容:
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
1.5.3 集群软件安装¶
#查看指定版本
yum list kubeadm.x86_64 --showduplicates | sort -r
yum list kubelet.x86_64 --showduplicates | sort -r
yum list kubectl.x86_64 --showduplicates | sort -r
#安装指定版本
yum -y install --setopt=obsoletes=0 kubeadm-1.25.3-0 kubelet-1.25.3-0 kubectl-1.25.3-0
1.5.4 配置kubelet¶
为了实现docker使用的cgroup driver与kubelet使用的cgroup的一致性,建议修改如下文件内容。
#vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
设置kubelet为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
systemctl enable kubelet
1.5.5 集群镜像准备¶
只需要在node1 Master节点上执行如下下载镜像命令即可,这里先使用kubeadm查询下镜像。
[root@node1 ~]#kubeadm config images list --kubernetes-version=v1.25.3
registry.k8s.io/kube-apiserver:v1.25.3
registry.k8s.io/kube-controller-manager:v1.25.3
registry.k8s.io/kube-scheduler:v1.25.3
registry.k8s.io/kube-proxy:v1.25.3
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.4-0
registry.k8s.io/coredns/coredns:v1.9.3
编写下载镜像脚本image_download.sh:
#!/bin/bash
images_list='
registry.k8s.io/kube-apiserver:v1.25.3
registry.k8s.io/kube-controller-manager:v1.25.3
registry.k8s.io/kube-scheduler:v1.25.3
registry.k8s.io/kube-proxy:v1.25.3
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.4-0
registry.k8s.io/coredns/coredns:v1.9.3
'
for i in $images_list
do
docker pull $i
done
docker save -o k8s-1-25-3.tar $images_list
以上脚本准备完成之后,执行命令:sh image_download.sh 进行镜像下载
注意:下载时候需要科学上网,否则下载不下来。也可以使用资料中的“k8s-1-25-3.tar”下载好的包。
如果下载不下来,使用资料中打包好的k8s-1-25-3.tar,将镜像导入到docker中¶
docker load -i k8s-1-25-3.tar
1.5.6 集群初始化¶
只需要在Master节点执行如下初始化命令即可。
[root@node1 ~]# kubeadm init --kubernetes-version=v1.25.3 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.179.4
注意:--apiserver-advertise-address=192.168.179.4 要写当前主机Master IP
初始化过程中报错:
[init] Using Kubernetes version: v1.25.3
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E1102 20:14:29.494424 10976 remote_runtime.go:948] "Status from runtime service
failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"time="2022-11-02T20:14:29+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alp
ha2.RuntimeService", error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
执行如下命令,重启containerd后,再次init 初始化。
[root@node1 ~]# rm -rf /etc/containerd/config.toml
[root@node1 ~]# systemctl restart containerd
初始化完成后,结果如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.179.4:6443 --token tpynmm.7picylv5i83q9ghw \
--discovery-token-ca-cert-hash sha256:2924026774d657b8860fbac4ef7698e90a3811137673af45e533c91e567a1529
1.5.7 集群应用客户端管理集群文件准备¶
参照初始化的内容来执行如下命令:
[root@node1 ~]# mkdir -p $HOME/.kube
[root@node1 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@node1 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@node1 ~]# export KUBECONFIG=/etc/kubernetes/admin.conf
1.5.8 集群网络准备¶
1.5.8.1 calico安装¶
K8s使用calico部署集群网络,安装参考网址:https://projectcalico.docs.tigera.io/about/about-calico,k8s 1.25.3 匹配 calico版本为 v3.24.5。
只需要在Master节点安装即可。
#下载operator资源清单文件
wget https://docs.projectcalico.org/manifests/tigera-operator.yaml --no-check-certificate
#应用资源清单文件,创建operator
kubectl create -f tigera-operator.yaml
#通过自定义资源方式安装
wget https://docs.projectcalico.org/manifests/custom-resources.yaml --no-check-certificate
#修改文件第13行,修改为使用kubeadm init ----pod-network-cidr对应的IP地址段
# vim custom-resources.yaml 【修改和增加以下加粗内容】
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
ipPools:
- blockSize: 26
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
nodeAddressAutodetectionV4:
interface: ens.*
#应用清单文件
kubectl create -f custom-resources.yaml
#监视calico-sysem命名空间中pod运行情况
watch kubectl get pods -n calico-system
[root@node1 ~]# watch kubectl get pods -n calico-system
Every 2.0s: kubectl get pods -n calico-system Thu Nov 3 14:14:30 2022
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-65648cd788-flmk4 1/1 Running 0 2m21s
calico-node-chnd5 1/1 Running 0 2m21s
calico-node-kc5bx 1/1 Running 0 2m21s
calico-node-s2cp5 1/1 Running 0 2m21s
calico-typha-d76595dfb-5z6mg 1/1 Running 0 2m21s
calico-typha-d76595dfb-hgg27 1/1 Running 0 2m19s
#删除 master 上的 taint
[root@node1 ~]# kubectl taint nodes --all node-role.kubernetes.io/master-
taint "node-role.kubernetes.io/master" not found
taint "node-role.kubernetes.io/master" not found
taint "node-role.kubernetes.io/master" not found
#已经全部运行
[root@node1 ~]# kubectl get pods -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-65648cd788-ktjrh 1/1 Running 0 110m
calico-node-dvprv 1/1 Running 0 110m
calico-node-nhzch 1/1 Running 0 110m
calico-node-q44gh 1/1 Running 0 110m
calico-typha-6bc9d76554-4bv77 1/1 Running 0 110m
calico-typha-6bc9d76554-nkzxq 1/1 Running 0 110m
#查看kube-system命名空间中coredns状态,处于Running状态表明联网成功。
[root@node1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-565d847f94-bjtlh 1/1 Running 0 19h
coredns-565d847f94-wlxmf 1/1 Running 0 19h
etcd-node1 1/1 Running 0 19h
kube-apiserver-node1 1/1 Running 0 19h
kube-controller-manager-node1 1/1 Running 0 19h
kube-proxy-bgpz2 1/1 Running 0 19h
kube-proxy-jlltp 1/1 Running 0 19h
kube-proxy-stfrx 1/1 Running 0 19h
kube-scheduler-node1 1/1 Running 0 19h
1.5.8.2 calico客户端安装¶
主要用来验证k8s集群节点网络是否正常。这里只需要在Master节点安装就可以。
#下载二进制文件,注意,这里需要检查calico 服务端的版本,客户端要与服务端版本保持一致,这里没有命令验证calico的版本,所以安装客户端的时候安装最新版本即可。
curl -L https://github.com/projectcalico/calico/releases/download/v3.24.3/calicoctl-linux-amd64 -o calicoctl
#安装calicoctl
mv calicoctl /usr/bin/
#为calicoctl添加可执行权限
chmod +x /usr/bin/calicoctl
#查看添加权限后文件
ls /usr/bin/calicoctl
#查看calicoctl版本
[root@node1 ~]# calicoctl version
Client Version: v3.24.1
Git commit: 83493da01
Cluster Version: v3.24.3
Cluster Type: typha,kdd,k8s,operator,bgp,kubeadm
通过~/.kube/config连接kubernetes集群,查看已运行节点
[root@node1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
node1
1.5.9 集群工作节点添加¶
这里在node2,node3 worker节点上执行命令,将worker节点加入到k8s集群。
[root@node2 ~]# kubeadm join 192.168.179.4:6443 --token tpynmm.7picylv5i83q9ghw \
--discovery-token-ca-cert-hash sha256:2924026774d657b8860fbac4ef7698e90a3811137673af45e533c91e567a1529
[root@node3 ~]# kubeadm join 192.168.179.4:6443 --token tpynmm.7picylv5i83q9ghw \
--discovery-token-ca-cert-hash sha256:2924026774d657b8860fbac4ef7698e90a3811137673af45e533c91e567a1529
注意:如果以上node2,node3 Worker节点已经错误的加入到Master节点,需要在Worker节点执行如下命令清除对应的信息,然后再次加入即可。
#重置kubeadm
[root@node2 ~]# kubeadm reset
#删除k8s配置文件和证书文件
[root@node2 kubernetes]# rm -f /etc/kubernetes/kubelet.conf
[root@node2 kubernetes]# rm -f /etc/kubernetes/pki/ca.crt
#重置kubeadm
[root@node3 ~]# kubeadm reset
#删除k8s配置文件和证书文件
[root@node3 kubernetes]# rm -f /etc/kubernetes/kubelet.conf
[root@node3 kubernetes]# rm -f /etc/kubernetes/pki/ca.crt
此外如果忘记了node join加入master节点的命令,可以按照以下步骤操作:
#查看discovery-token-ca-cert-hash
[root@node1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
#查看token
[root@node1 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION
EXTRA GROUPS1945mk.ved91lifrc8l0zj9 23h 2022-11-10T08:14:46Z authentication,signing The default bootstrap token generated by 'kubeadm init'.
system:bootstrappers:kubeadm:default-node-token
#Node节点加入集群
[root@node1 ~]# kubeadm join 192.168.179.4:6443 --token 查询出来的token \
--discovery-token-ca-cert-hash 查询出来的hash码
在master节点上操作,查看网络节点是否添加
[root@node1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
node1
node2
node3
1.5.10 验证集群可用性¶
使用命令查看所有的节点:
[root@node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 20h v1.25.3
node2 Ready <none> 20h v1.25.3
node3 Ready <none> 20h v1.25.3
查看集群健康情况:
[root@node1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
etcd-0 Healthy {"health":"true","reason":""}
scheduler Healthy ok
controller-manager Healthy ok
查看kubernetes集群pod运行情况:
[root@node1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-565d847f94-bjtlh 1/1 Running 0 20h
coredns-565d847f94-wlxmf 1/1 Running 0 20h
etcd-node1 1/1 Running 0 20h
kube-apiserver-node1 1/1 Running 0 20h
kube-controller-manager-node1 1/1 Running 0 20h
kube-proxy-bgpz2 1/1 Running 1 20h
kube-proxy-jlltp 1/1 Running 1 20h
kube-proxy-stfrx 1/1 Running 0 20h
kube-scheduler-node1 1/1 Running 0 20h
查看集群信息:
[root@node1 ~]# kubectl cluster-info
Kubernetes control plane is running at https://192.168.179.4:6443
CoreDNS is running at https://192.168.179.4:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
1.5.11 K8s集群其他一些配置¶
当在Worker节点上执行kubectl命令管理时会报如下错误:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
只要把master上的管理文件/etc/kubernetes/admin.conf拷贝到Worker节点的$HOME/.kube/config就可以让Worker节点也可以实现kubectl命令管理。
#在Worker节点创建.kube目录
[root@node2 ~]# mkdir /root/.kube
[root@node3 ~]# mkdir /root/.kube
#在master节点做如下操作
[root@node1 ~]# scp /etc/kubernetes/admin.conf node2:/root/.kube/config
[root@node1 ~]# scp /etc/kubernetes/admin.conf node3:/root/.kube/config
#在worker 节点验证
[root@node2 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 24h v1.25.3
node2 Ready <none> 24h v1.25.3
node3 Ready <none> 24h v1.25.3
[root@node3 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 24h v1.25.3
node2 Ready <none> 24h v1.25.3
node3 Ready <none> 24h v1.25.3
此外,无论在Master节点还是Worker节点使用kubenetes 命令时,默认不能自动补全,例如:kubectl describe 命令中describe不能自动补全,使用非常不方便,那么这里配置命令自动补全功能。
在所有的kubernetes节点上安装bash-completion并source执行,同时配置下开机自动source,每次开机能自动补全命令。
#安装bash-completion 并 source
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
kubectl completion bash > ~/.kube/completion.bash.inc
source '/root/.kube/completion.bash.inc'
#实现用户登录主机自动source ,自动使用命令补全
vim ~/.bash_profile 【加入加粗这一句】
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
source '/root/.kube/completion.bash.inc'
PATH=$PATH:$HOME/bin
export PATH
1.6 Kubernetes集群UI及主机资源监控¶
1.6.1 Kubernetes dashboard作用¶
通过Kubernetes dashboard能够直观了解Kubernetes集群中运行的资源对象,通过dashboard可以直接管理(创建、删除、重启等操作)资源对象。
1.6.2 获取Kubernetes dashboard资源清单文件¶
这里只需要在Kubernetes Master节点上来下载应用资源清单文件即可。这里去github.com 搜索“kubernetes dashboard”即可,找到匹配Kubernetes 版本的dashboard,下载对应版本的dashboard yaml文件。
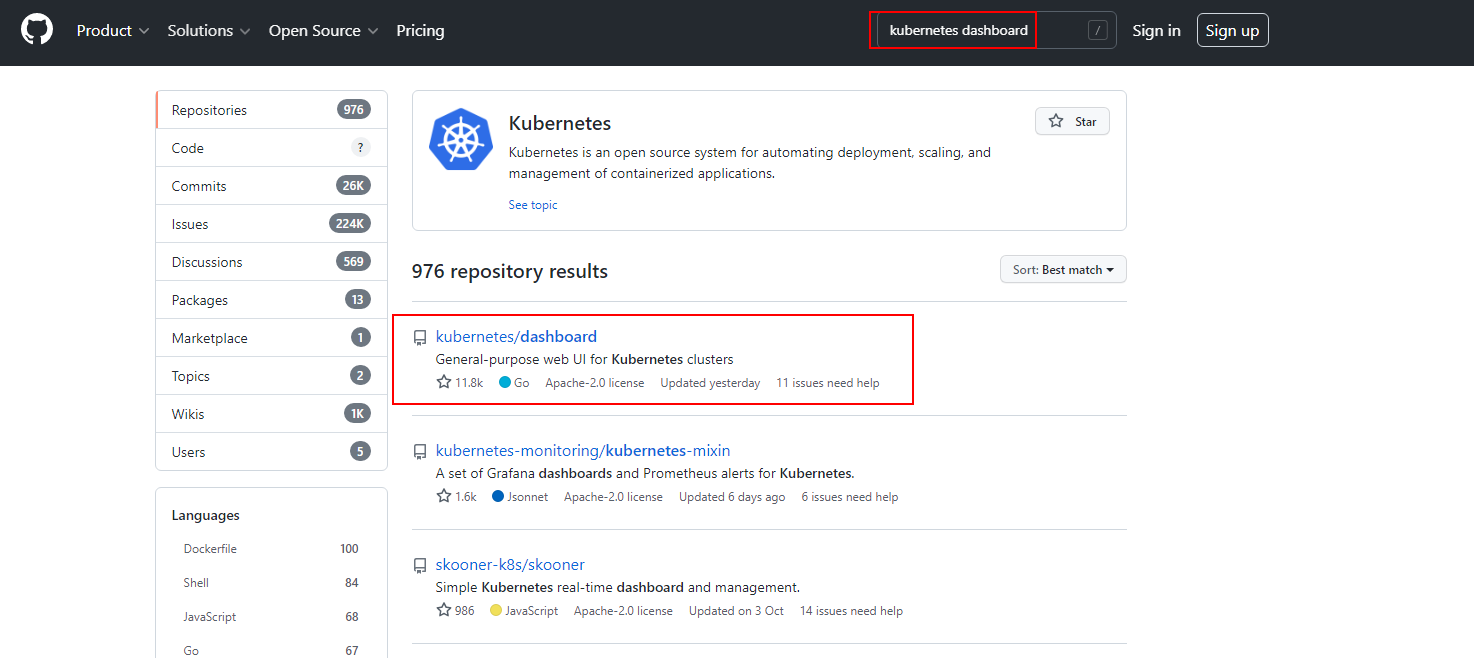
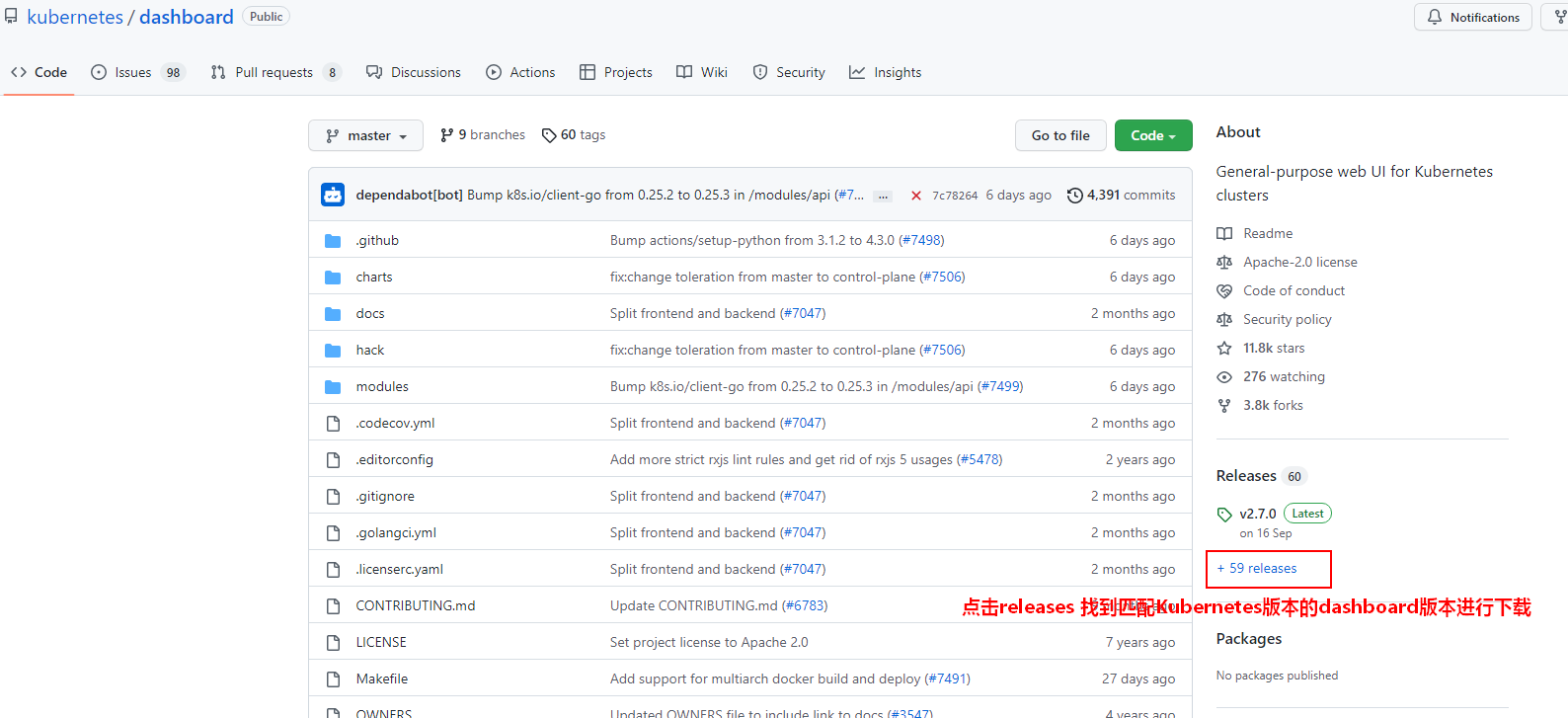
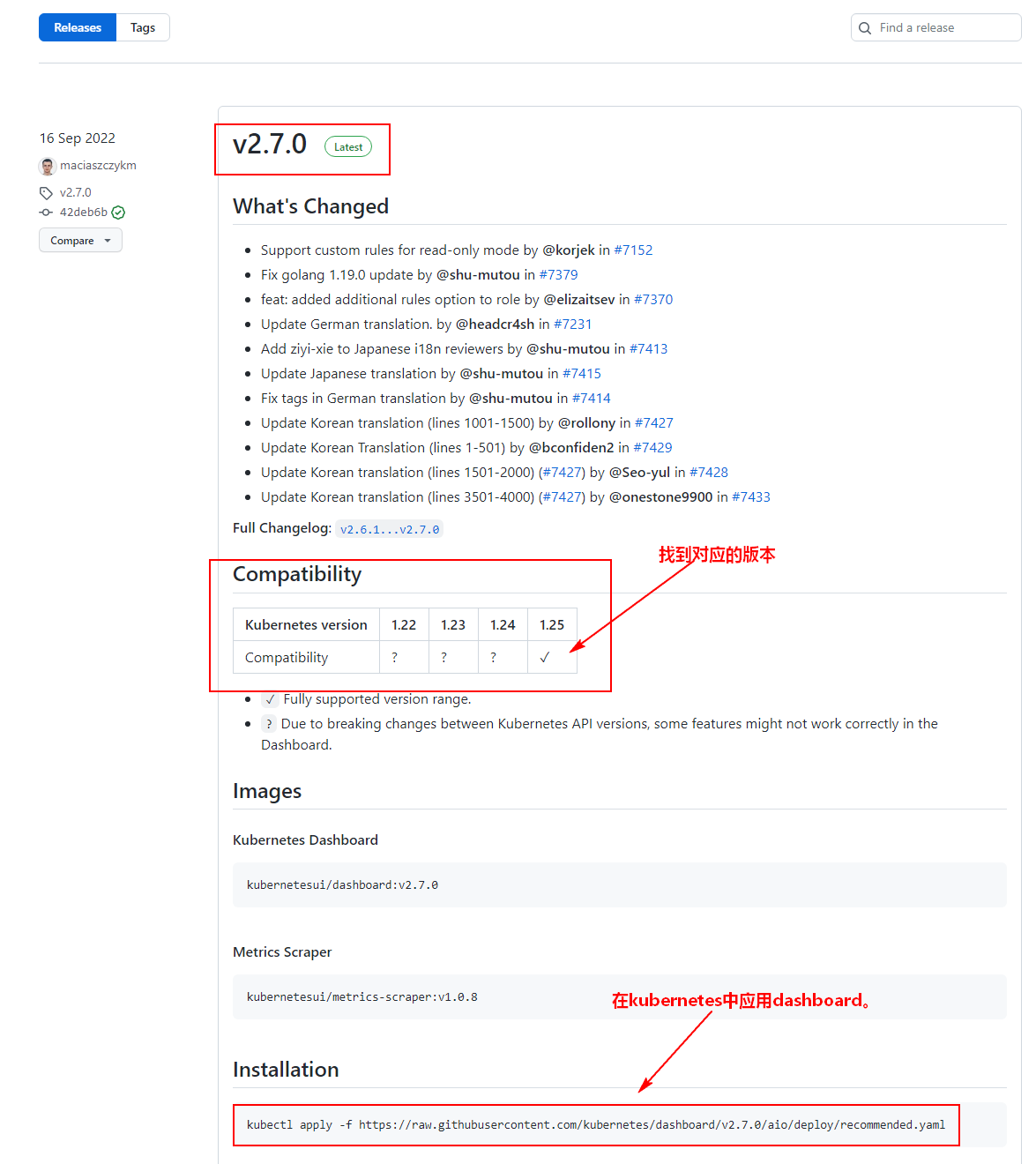
[root@node1 ~]# mkdir kube-dashboard
[root@node1 ~]# cd kube-dashboard/
[root@node1 kube-dashboard]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
 对应yaml文件下载完成后,为了方便后续在容器主机上访问,在yaml文件中添加对应的NodePort类型、端口以及修改登录kubernetes dashboard的用户。
对应yaml文件下载完成后,为了方便后续在容器主机上访问,在yaml文件中添加对应的NodePort类型、端口以及修改登录kubernetes dashboard的用户。
#vi recommended.yaml 【只需要添加或修改以下加粗部分】
... ...
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30000
selector:
k8s-app: kubernetes-dashboard
... ....
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
注意:一定要把原来kind为ClusterRole下的name对应值kubernetes-dashboard修改为cluster-admin,不然进入UI后会报错。
#部署Kubernetes dashboard
[root@node1 kube-dashboard]# kubectl apply -f recommended.yaml
#查看部署是否成功,出现kubenetes-dashboard命名空间即可。
[root@node1 kube-dashboard]# kubectl get ns
NAME STATUS AGE
calico-apiserver Active 5h33m
calico-system Active 5h35m
default Active 23h
kube-node-lease Active 23h
kube-public Active 23h
kube-system Active 23h
kubernetes-dashboard Active 6s
tigera-operator Active 5h36m
[root@node1 kube-dashboard]# kubectl get pod,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-64bcc67c9c-gsqsn 1/1 Running 0 112s
pod/kubernetes-dashboard-5c8bd6b59-x4p8r 1/1 Running 0 112s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.106.178.119 <none> 8000/TCP 112s
service/kubernetes-dashboard NodePort 10.96.4.46 <none> 443:30000/TCP 113s
1.6.3 访问Kubernetes dashboard¶
WebUI访问Kubernetes dashboard:https://192.168.179.4:30000
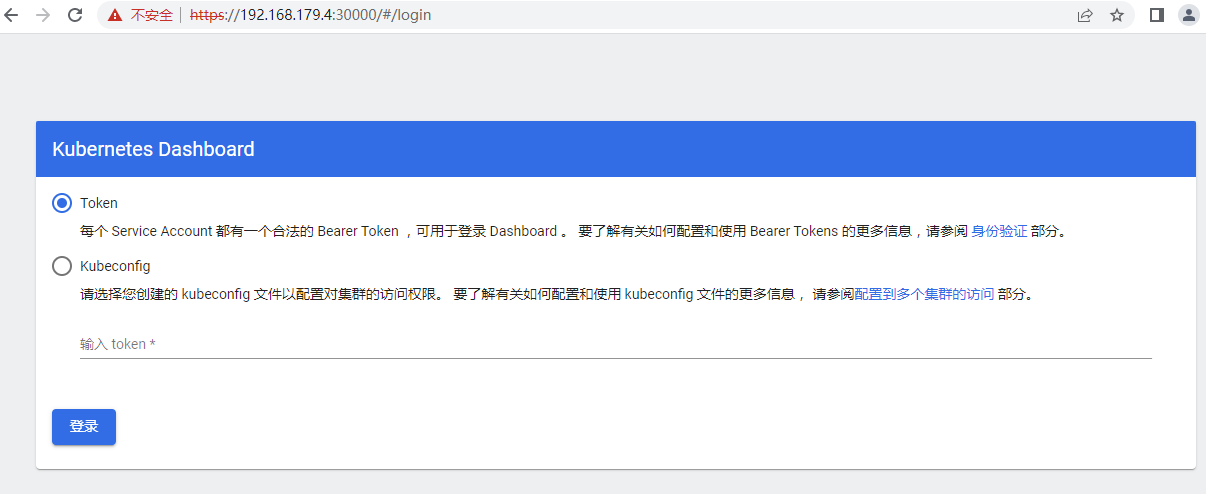
选择“Token”,使用如下命令获取Kubernetes的Token:
#注意最后的kubernetes-dashboard 为部署dashboard创建的serviceaccounts
[root@node1 kube-dashboard]# kubectl -n kubernetes-dashboard create token kubernetes-dashboard
eyJhbGciOiJSUzI1NiIsImtpZCI6IlFDVlB4Wng3REtPNGZhd05sYnJvbFBWbE9iS2pDYmtEYUZyQ2VaSjA0MjAifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjY3NDgxODQ0LCJpYXQiOjE2Njc0NzgyNDQsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInVpZCI6ImY3ZGQ0YTI1LTEwOTAtNDYyZC04N2JhLTM4NjNlM2Q3MjQxNCJ9fSwibmJmIjoxNjY3NDc4MjQ0LCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQifQ.b0S3YAJrFTUb-pgiPLp3kuB510sL7r9LPvmeO5kXM86ZRJhbGOFsD-CK-ONQnDF2EVAg76YsV_I7Afv_P_RkSspfy0AnBDUFj-LBufocX1cofCHc1_dErVbCQ5MvUsnw67PvpdcZMWuAndYhMVorOIxOc_RxhUM6tre3kuZJ40r2W-8Kbgd4b3HvLeaE2gJNTofn5ChYLkDd7TQYqRtmZN14l6CFZMUSl1dHqSuWhUncNHELhI8uRRD1pfFmMlYrqkZOTqzkw5_czMFrE9yIFKktMqT3wpvRVWFzYZFd9SpGMoQtshKjR3h508N-KG2Ob3PQYbvpBdoap2UjOjQJVg
将以上生成的Token复制粘贴到登录的WebUI页面中登录Kubernetes DashBoard。注意:以上token复制时不要有空格。
1.7 Kuberneters 部署案例¶
这里为了强化对Kubernetes集群的理解,我们基于Kubernetes集群进行部署nginx服务,nginx服务我们设置2个副本,同时将nginx服务端口80暴露到宿主机上。在kubernetes中,我们可以通过WebUI来添加服务,也可以在命令行中通过应用yaml来部署服务,下面以命令行部署nginx服务为例:
1) 创建资源清单文件
- nginx.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
spec:
selector:
matchLabels:
app: nginx
env: test
owner: rancher
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
env: test
owner: rancher
spec:
containers:
- name: nginx-test
image: nginx:1.19.9
ports:
- containerPort: 80
- nginx-service.yaml :
apiVersion: v1
kind: Service
metadata:
name: nginx-test
labels:
run: nginx
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
nodePort: 30080
selector:
owner: rancher
2) 应用资源清单文件
[root@node1 nginx-test]# kubectl apply -f nginx.yaml
[root@node1 nginx-test]# kubectl apply -f nginx-service.yaml
3) 验证
[root@node1 test]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-test-74845c57fb-7tl86 1/1 Running 0 45s
pod/nginx-test-74845c57fb-qjc6d 1/1 Running 0 45s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 123m
service/nginx-test NodePort 10.107.171.29 <none> 80:30204/TCP 21s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-test 2/2 2 2 45s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-test-74845c57fb 2 2 2 45s
4) 访问验证
访问任意kubernetes集群的节点30080端口查看nginx服务是正常,例如:浏览器输入node1:30080

5) 删除nginix服务
[root@node1 nginx-test]# kubectl delete -f nginx-service.yaml
[root@node1 nginx-test]# kubectl delete -f nginx.yaml
1.8 Flink基于Kubernetes部署¶
Flink基于Kubernetes部署时支持两种模式:Kubernetes部署模式和Native Kubernetes 部署模式。Flink从1.2版本开始支持Kubernetes部署模式,从Flink1.10版本开始Flink支持Native Kubernetes部署模式。
- Kubernetes部署模式
Flink Kubernetes这种部署模式是把JobManager和TaskManager等进程放入容器,在Kubernetes管理和运行,这与我们将Java Web应用做成docker镜像再运行在Kubernetes中道理一样,都是使用kubernetes中的kubectl命令来操作。
- Native Kubernetes部署模式
Native Kubernetes部署模式是在Flink安装包中有个工具,此工具可以向Kubernetes的Api Server 发送请求,例如:创建Flink Master ,并且可以和FlinkMaster通讯,用于提交任务,我们只要用好Flink 安装包中的工具即可,无需在Kuberbetes上执行kubectl操作。
Flink与Kubernetes整合时要求Kubernetes版本不能低于1.9,我们这里使用的Kubernetes版本是1.25.3版本。
1.8.1 Kubernetes部署¶
Flink 基于Kubernetes部署支持Session Cluster模式和Application Cluster模式部署。Session Cluster模式即可以在一个Flink集群中运行多个作业,这些作业公用JobManager和TaskManager。Application Cluster模式即一个作业使用单独的一个专用Flink集群,每个Flink作业的JobManager和TaskManager隔离。无论是Session Cluster模式还是Application Cluster模式都支持JobManager的HA 部署。下面分别介绍并测试。
1.8.1.1 Session Cluster部署¶
Flink Session集群作为Kubernetes Deployment来运行的,可以在一个基于K8s 部署的Session Cluster 中运行多个Flink job,在Kubernetes 上部署Flink Session 集群时,一般至少包含三个组件:
- 运行JobManager的Deployment
- 运行TaskManager的Deployment
- 暴露JobManager上的REST和UI端口的Service
1.8.1.1.1 非HA Session Cluster部署及测试¶
1.8.1.1.1.1 准备deployment文件¶
- flink-configuration-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
parallelism.default: 2
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
- jobmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123
- name: blob-server
port: 6124
- name: webui
port: 8081
selector:
app: flink
component: jobmanager
- jobmanager-rest-service.yaml
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-rest
spec:
type: NodePort
ports:
- name: rest
port: 8081
targetPort: 8081
nodePort: 30081
selector:
app: flink
component: jobmanager
- jobmanager-session-deployment-non-ha.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
containers:
- name: jobmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
args: ["jobmanager"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
hostPath:
path: /etc/localtime
type: ''
- taskmanager-session-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
containers:
- name: taskmanager
image: flink:1.16.0-scala_2.12-java8
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
hostPath:
path: /etc/localtime
type: ''
注意:关于Flink的镜像可以从https://hub.docker.com/网站中搜索下载。以上配置文件可以从资料“flink-nonha-session.zip”中获取。
1.8.1.1.1.2 部署yaml 文件¶
在对应的目录中执行如下命令:
kubectl create -f ./flink-configuration-configmap.yaml
kubectl create -f ./jobmanager-rest-service.yaml
kubectl create -f ./jobmanager-service.yaml
kubectl create -f ./jobmanager-session-deployment-non-ha.yaml
kubectl create -f ./taskmanager-session-deployment.yaml
注意:也可以进入对应yaml文件目录,直接执行 kubectl create -f ./ 全部部署也可以。
1.8.1.1.1.3 验证部署情况¶
[root@node1 flink-nonha-session]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/flink-jobmanager-6f45bb68f5-rnd5p 1/1 Running 0 81s
pod/flink-taskmanager-d5f89bb47-jjtz7 1/1 Running 0 81s
pod/flink-taskmanager-d5f89bb47-rmfff 1/1 Running 0 81s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flink-jobmanager ClusterIP 10.107.162.123 <none> 6123/TCP,6124/TCP,8081/TCP 82s
service/flink-jobmanager-rest NodePort 10.102.57.189 <none> 8081:30081/TCP 82s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flink-jobmanager 1/1 1 1 81s
deployment.apps/flink-taskmanager 2/2 2 2 81s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flink-jobmanager-6f45bb68f5 1 1 1 81s
replicaset.apps/flink-taskmanager-d5f89bb47 2 2 2 81s
在浏览器输入:http://192.168.179.4:30081/即可访问Flink Session集群WebUI。浏览器中输入的ip可以是K8s集群中任意节点的IP。
1.8.1.1.1.4 停止集群¶
kubectl delete -f ./flink-configuration-configmap.yaml
kubectl delete -f ./jobmanager-rest-service.yaml
kubectl delete -f ./jobmanager-service.yaml
kubectl delete -f ./jobmanager-session-deployment-non-ha.yaml
kubectl delete -f ./taskmanager-session-deployment.yaml
注意:也可以进入对应yaml文件目录,直接执行 kubectl delete -f ./ 全部部署也可以。
1.8.1.1.1.5**任务提交与测试**¶
基于K8s的Flink Standalone 集群我们可以通过Flink WebUI来提交Flink任务,也可以通过Flink客户端命令提交任务。
1) 基于WebUI提交Flink任务
这里编写读取socket端口数据实时统计WordCount的Flink代码,代码如下:
package com.mashibing.flinkjava.code.chapter_k8s;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Flink 基于K8s 测试代码:
* 读取socket端口数据实时统计WordCount
*/
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> sourceDS = env.socketTextStream("192.168.179.8", 9999);
SingleOutputStreamOperator<Tuple2<String, Long>> tupleDS = sourceDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}
});
KeyedStream<Tuple2<String, Long>, String> keyedStream = tupleDS.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> stringLongTuple2) throws Exception {
return stringLongTuple2.f0;
}
});
keyedStream.sum(1).print();
env.execute();
}
}
注意:后续基于Kubernetes运行Flink任务都基于此任务测试。
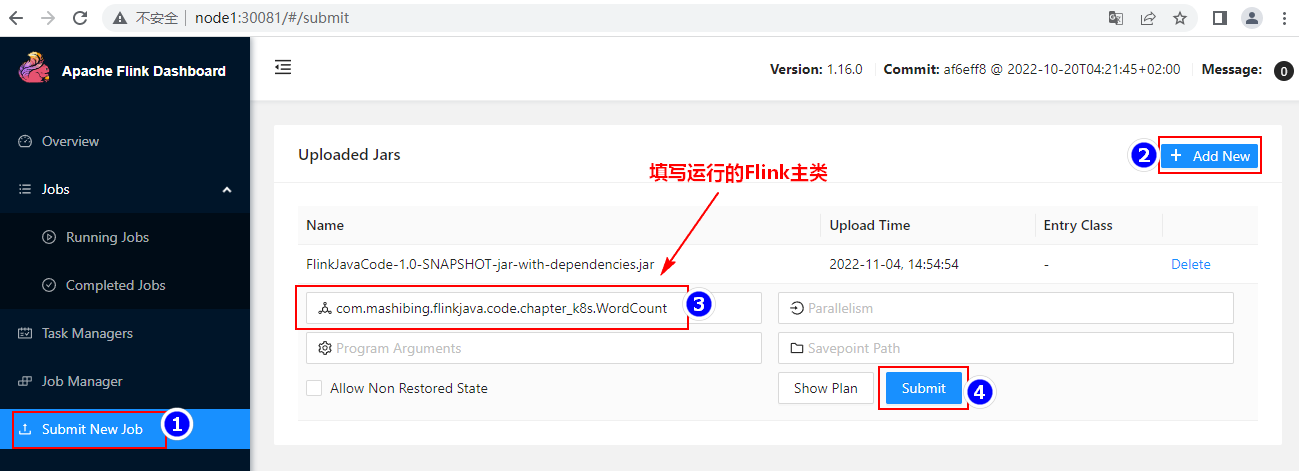
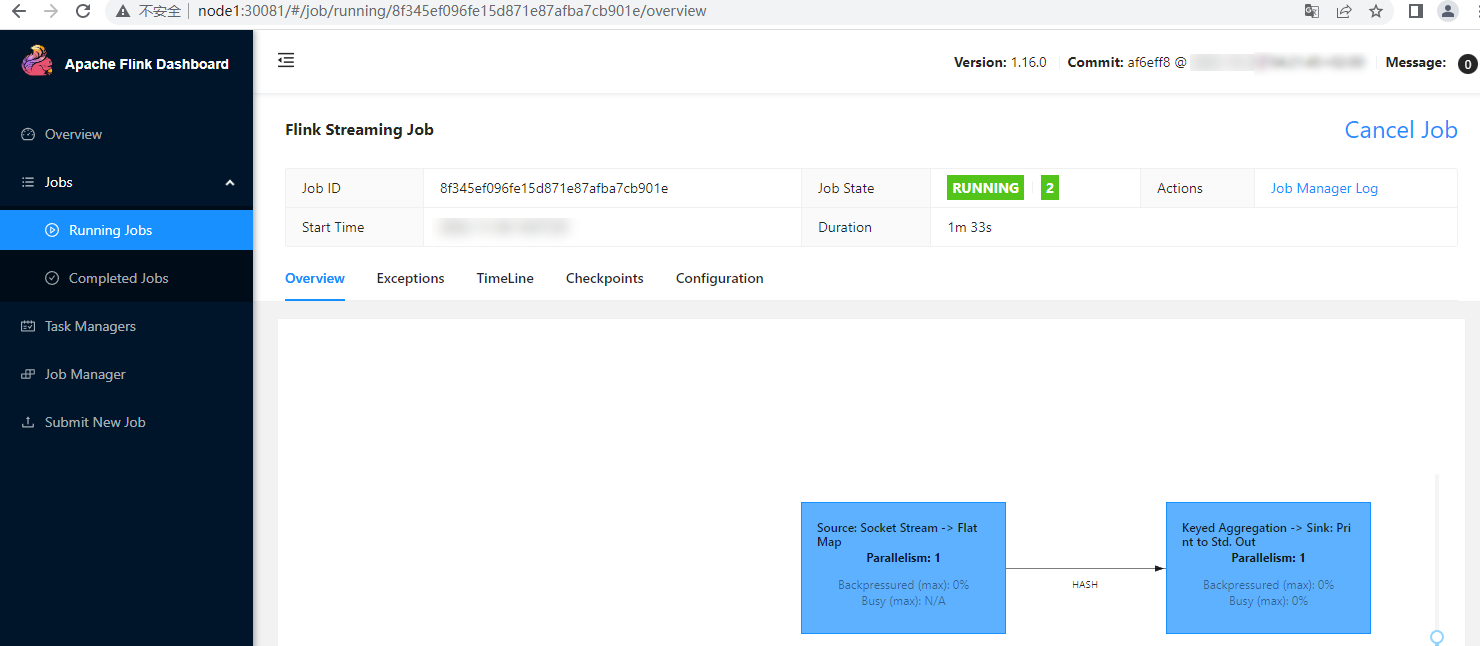
编写好代码后将以上代码进行打包,在对应的节点上启动对应的socket服务(nc -lk 9999),这里代码中选择的是node5 9999端口。通过WebUI进行上传执行,具体操作如下:

在node5 socket 9999端口输入数据:
[root@node5 ~]# nc -lk 9999
hello zhangsan
hello lisi
hello wangwu
向K8S部署的Flink集群中提交应用程序如果打印结果到控制台不支持在WebUI中的TaskManager中查看对应的Console日志,主要原因是K8S 基于Docker运行Flink TaskExecutor和JobMaster 进程时不会将STDOUT日志重定向到文件中。这里可以通过kubectl logs + pod 来查看对应的输出日志。
首先在WebUI页面中查看对应sink运行所在的TaskManager IP。

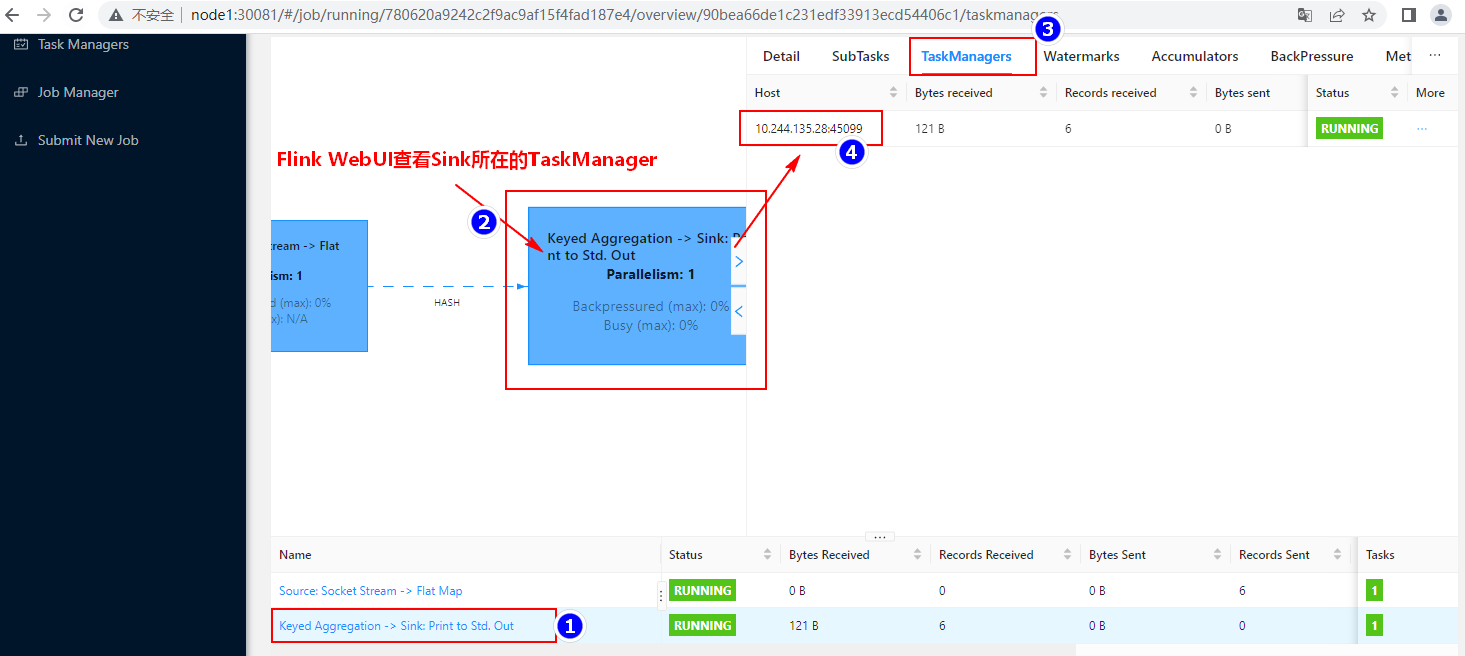
通过TaskManager ip 确定输出结果的TaskManager Pod :
[root@node1 flink]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
flink-jobmanager-6f45bb68f5-4dbkp 1/1 Running 0 14m 10.244.135.27 node3 <none> <none>
flink-taskmanager-d5f89bb47-d5ljm 1/1 Running 0 14m 10.244.104.19 node2 <none> <none>
flink-taskmanager-d5f89bb47-jmlmr 1/1 Running 0 14m 10.244.135.28 node3 <none> <none>
通过以上查询可以根据TaskManager IP 可以找到名为“flink-taskmanager-d5f89bb47-jmlmr”的Pod。查看该pod日志,就可以看到输出的结果:
[root@node1 flink]# kubectl logs flink-taskmanager-d5f89bb47-jmlmr
... ...
2022-11-04 07:49:48,208 INFO org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction [] - Connecting to server socket 192.168.1
79.8:99992022-11-04 07:49:48,210 INFO org.apache.flink.runtime.taskmanager.Task [] - Keyed Aggregation -> Sink: Print to Std. Out (1/1
)#0 (124df880f6de0d84f0d085586c52b6d9_90bea66de1c231edf33913ecd54406c1_0_0) switched from INITIALIZING to RUNNING.(hello,1)
(zhangsan,1)
(hello,2)
(lisi,1)
(hello,3)
(wangwu,1)
2) 通过客户端命令方式提交任务
这种方式只需要在任意能连接到Kubernetes集群的节点上通过Flink客户端命令提交Flink任务节即可。该节点需要有Flink的安装包,这里选择node4节点上传Flink的安装包并解压到“/software/flink-1.16.0”路径中。
在node5节点上启动对应的Socket服务,执行如下命令进行客户端命令提交Flink任务:
[root@node4 ~]# cd /software/flink-1.16.0/bin/
[root@node4 bin]# ./flink run -m 192.168.179.4:30081 -c com.mashibing.flinkjava.code.chapter_k8s.WordCount /software/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
向socket端口输入数据,通过kubectl logs + pods 方式查看对应的实时结果即可。
1.8.1.1.2 HA Session Cluster部署及测试¶
通过以上基于Kubernetes 部署Flink Session集群,我们部署了1个JobManager和2个TaskManager,这里说的HA Session集群部署,就是当JobManager挂掉时,能正常切换到另外的JobManager中继续调度任务。实际上在Kubernets集群中当JobManager容器挂掉之后,Kubernetes集群会自动重新运行新的JobManager。所以基于Kubernets不部署HA 模式模式也没有问题,这里为了更快的进行恢复Flink任务,我们也可以基于Kubernetes配置HA Session模式。
配置HA Session模式与非HA Session模式相比不再需要jobmanager-server.yaml文件。
1.8.1.1.2.1 准备deployment文件¶
- flink-configuration-configmap.yaml
该yaml文件相比于非HA Session模式增加了以下行:
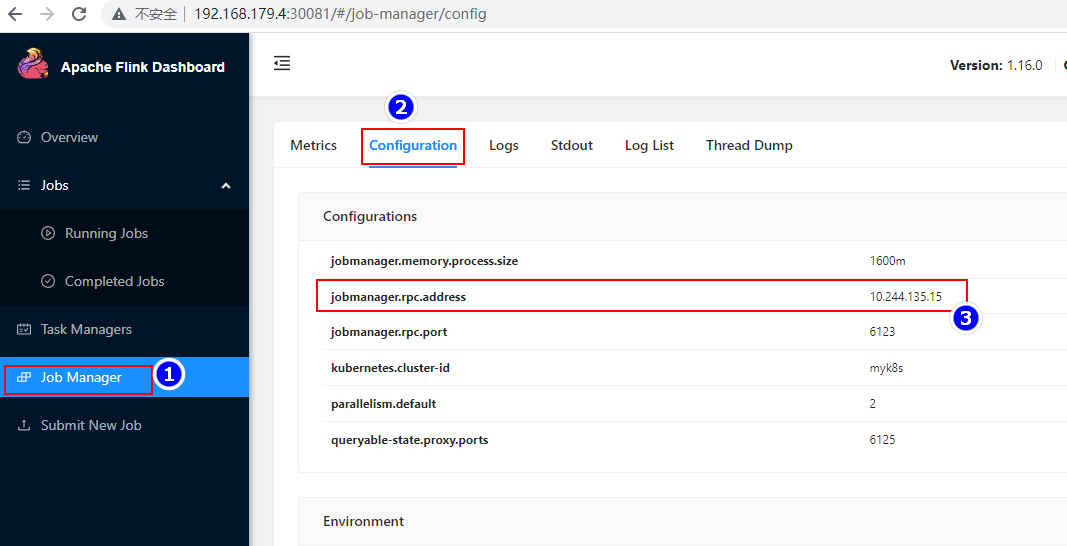
kubernetes.cluster-id: myk8s #给kubernets集群取个名字
high-availability: kubernetes #指定高可用模式
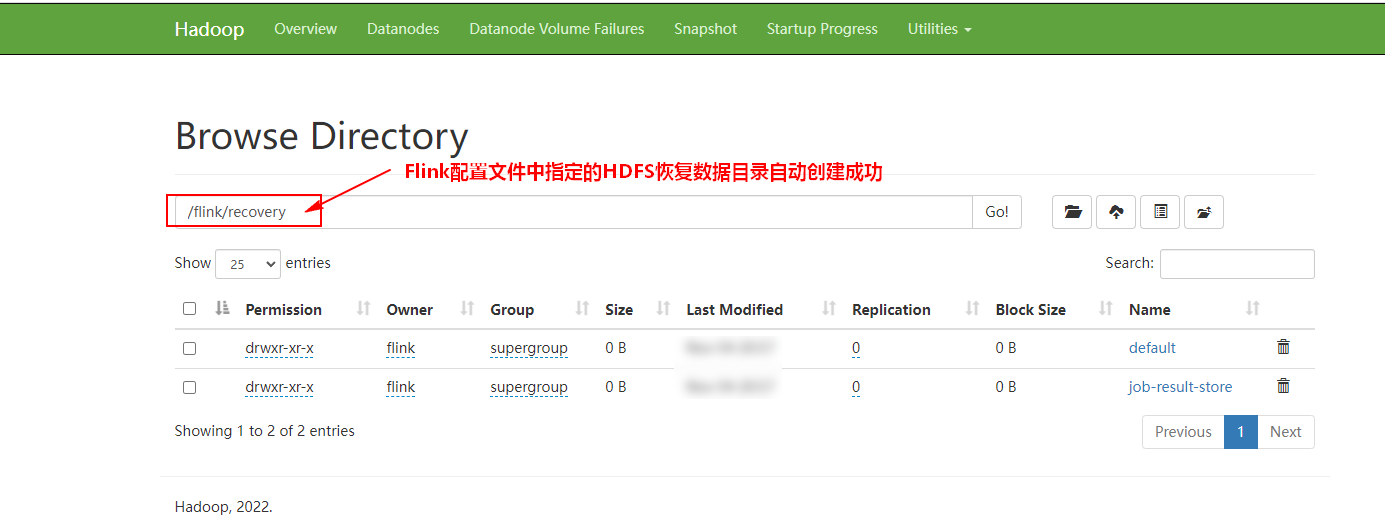
high-availability.storageDir: hdfs://mycluster/flink/recovery #指定元数据存储目录为hdfs路径
restart-strategy: fixed-delay #指定重启策略
restart-strategy.fixed-delay.attempts: 10 #指定重启尝试次数
以上配置使用kubernetes来进行协调FlinkHA,部署相应flink-configuration-configmap.yaml文件后在Kubernetes中会额外生成<cluster-id>-xxx对应的configmap对象,此对象记录Flink 集群中提交的job元数据。
完整的flink-configuration-configmap.yaml文件如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
parallelism.default: 2
kubernetes.cluster-id: myk8s #给kubernets集群取个名字
high-availability: kubernetes #指定高可用模式
high-availability.storageDir: hdfs://mycluster/flink/recovery #指定元数据存储目录为hdfs路径
restart-strategy: fixed-delay #指定重启策略
restart-strategy.fixed-delay.attempts: 10 #指定重启尝试次数
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
- jobmanager-rest-service.yaml
该文件与非HA Session模式对应文件部署一样。
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-rest
spec:
type: NodePort
ports:
- name: rest
port: 8081
targetPort: 8081
nodePort: 30081
selector:
app: flink
component: jobmanager
- jobmanager-cluster-role.yaml
在k8s中是基于角色授权的,创建用户时需要绑定对应的角色,在JobManager HA 部署案例中需要操作对应的配置ConfigMap文件。这里通过jobmanager-cluster-role.yaml创建一个ClusterRole,然后再创建用户,将用户绑定到该集群角色,拥有对ConfigMap操作权限。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: configmaps-role #创建ClusterRole的名称
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["configmaps"] #指定操作的资源为configmaps
verbs: ["create", "edit", "delete","get", "watch", "list","update"] #指定操作的权限
以上创建完成,再创建一个用户叫flink-service-account,后续将用户绑定到该角色。
kubectl create serviceaccount flink-service-account
把flink-service-account用户绑定到集群角色:
kubectl create clusterrolebinding flink-role-binding-serviceaccount --clusterrole=configmaps-role --serviceaccount=default:flink-service-account
- jobmanager-session-deployment-ha.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
spec:
replicas: 2 #这里配置2个副本# Set the value to greater than 1 to start standby JobManagers
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
hostAliases: #向容器/etc/hosts中加入ip与节点名称映射,pod找HDFS集群时需要使用
- ip: 192.168.179.4
hostnames:
- "node1"
- ip: 192.168.179.5
hostnames:
- "node2"
- ip: 192.168.179.6
hostnames:
- "node3"
- ip: 192.168.179.7
hostnames:
- "node4"
- ip: 192.168.179.8
hostnames:
- "node5"
containers:
- name: jobmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: HADOOP_CLASSPATH #这里由于在flink pod内使用到HDFS ,需要把宿主机的HDFS配置文件挂载进来,并配置HADOOP_CLASSPATH环境变量,可以通过在宿主机执行echo `hadoop classpath`来参考这里导入的路径,记得要把Hadoop路径改成挂载到Pod中的路径
value: /opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
# The following args overwrite the value of jobmanager.rpc.address configured in the configuration config map to POD_IP.
args: ["jobmanager", "$(POD_IP)"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
mountPath: /opt/hadoop
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
serviceAccountName: flink-service-account #指定seviceAccountName 用户名
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
hostPath:
path: /etc/localtime
type: ''
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
hostPath:
path: /software/hadoop-3.3.4
type: ''
- taskmanager-session-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
hostAliases: #向容器/etc/hosts中加入ip与节点名称映射,pod找HDFS集群时需要使用
- ip: 192.168.179.4
hostnames:
- "node1"
- ip: 192.168.179.5
hostnames:
- "node2"
- ip: 192.168.179.6
hostnames:
- "node3"
- ip: 192.168.179.7
hostnames:
- "node4"
- ip: 192.168.179.8
hostnames:
- "node5"
containers:
- name: taskmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
env:
- name: HADOOP_CLASSPATH #这里由于在flink pod内使用到HDFS ,需要把宿主机的HDFS配置文件挂载进来,并配置HADOOP_CLASSPATH环境变量,可以通过在宿主机执行echo `hadoop classpath`来参考这里导入的路径,记得要把Hadoop路径改成挂载到Pod中的路径
value: /opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
mountPath: /opt/hadoop
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
serviceAccountName: flink-service-account #指定seviceAccountName 用户名
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
hostPath:
path: /etc/localtime
type: ''
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
hostPath:
path: /software/hadoop-3.3.4
type: ''
注意:关于Flink的镜像可以从https://hub.docker.com/网站中搜索下载。
由于在flink pod内使用到HDFS ,需要把宿主机的HDFS配置文件挂到Flink JobManager和TaskManager中并配置HADOOP_CLASSPATH环境变量,可以通过在宿主机执行echo hadoop classpath来参考HADOOP_CLASSPATH环境变量对应的value值路径,记得要把Hadoop路径改成挂载到Pod中的路径。
以上配置文件可以从资料“flink-ha-session.zip”中获取。
1.8.1.1.2.2 部署yaml 文件¶
由于HA模式使用到了HDFS集群,所以这里应该首先启动HDFS集群然后再部署对应的yaml文件。
#启动zookeeper
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
#启动HDFS集群
[root@node1 ~]# start-all.sh
部署之前记得执行上一小节中创建用户与绑定用户到角色命令,如果执行过不必重复创建执行。
kubectl create serviceaccount flink-service-account
kubectl create clusterrolebinding flink-role-binding-serviceaccount --clusterrole=configmaps-role --serviceaccount=default:flink-service-account
在对应的目录中执行如下命令,部署yaml文件
kubectl create -f ./flink-configuration-configmap.yaml
kubectl create -f ./jobmanager-cluster-role.yaml
kubectl create -f ./jobmanager-rest-service.yaml
kubectl create -f ./jobmanager-session-deployment-ha.yaml
kubectl create -f ./taskmanager-session-deployment.yaml
注意:也可以进入对应yaml文件目录,直接执行 kubectl create -f ./ 全部部署也可以。
1.8.1.1.2.3 验证部署情况¶
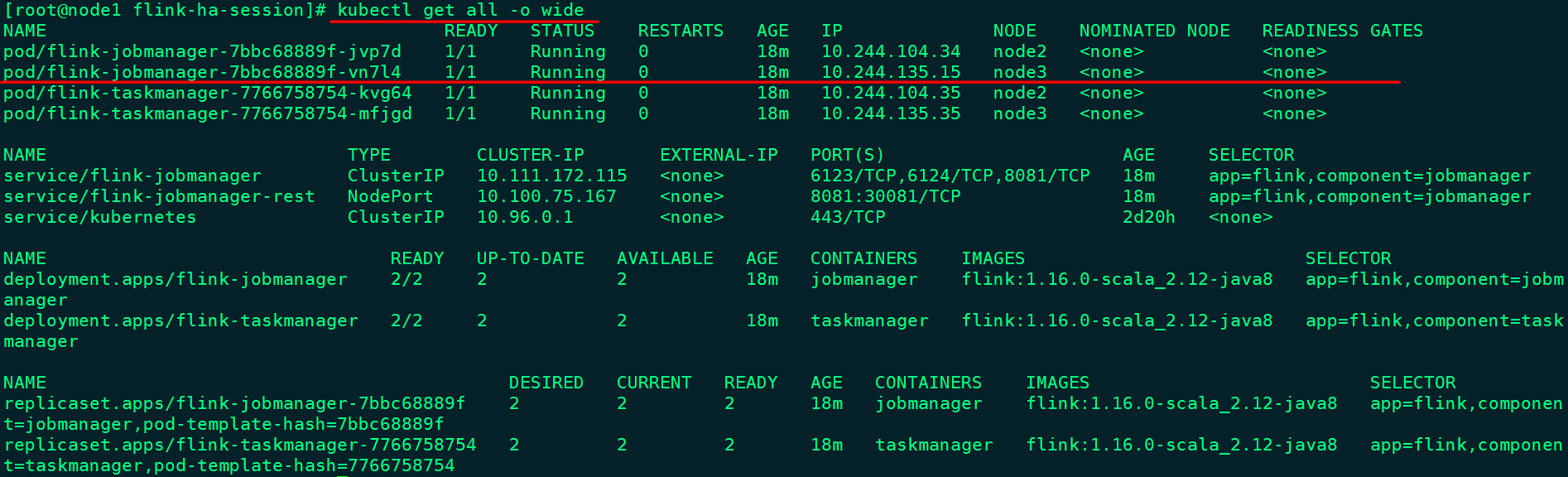
[root@node1 flink-ha-session]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/flink-jobmanager-7bbc68889f-jvp7d 1/1 Running 0 6m40s
pod/flink-jobmanager-7bbc68889f-vn7l4 1/1 Running 0 6m41s
pod/flink-taskmanager-7766758754-kvg64 1/1 Running 0 6m40s
pod/flink-taskmanager-7766758754-mfjgd 1/1 Running 0 6m41s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flink-jobmanager-rest NodePort 10.100.75.167 <none> 8081:30081/TCP 6m41s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d20h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flink-jobmanager 2/2 2 2 6m41s
deployment.apps/flink-taskmanager 2/2 2 2 6m41s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flink-jobmanager-7bbc68889f 2 2 2 6m41s
replicaset.apps/flink-taskmanager-7766758754 2 2 2 6m41s
在浏览器输入:http://192.168.179.4:30081/即可访问Flink Session集群WebUI。浏览器中输入的ip可以是K8s集群中任意节点的IP。
1.8.1.1.2.4 HA高可用验证¶
登录HDFS WebUI查看是否生成“hdfs://mycluster/flink/recovery”目录:
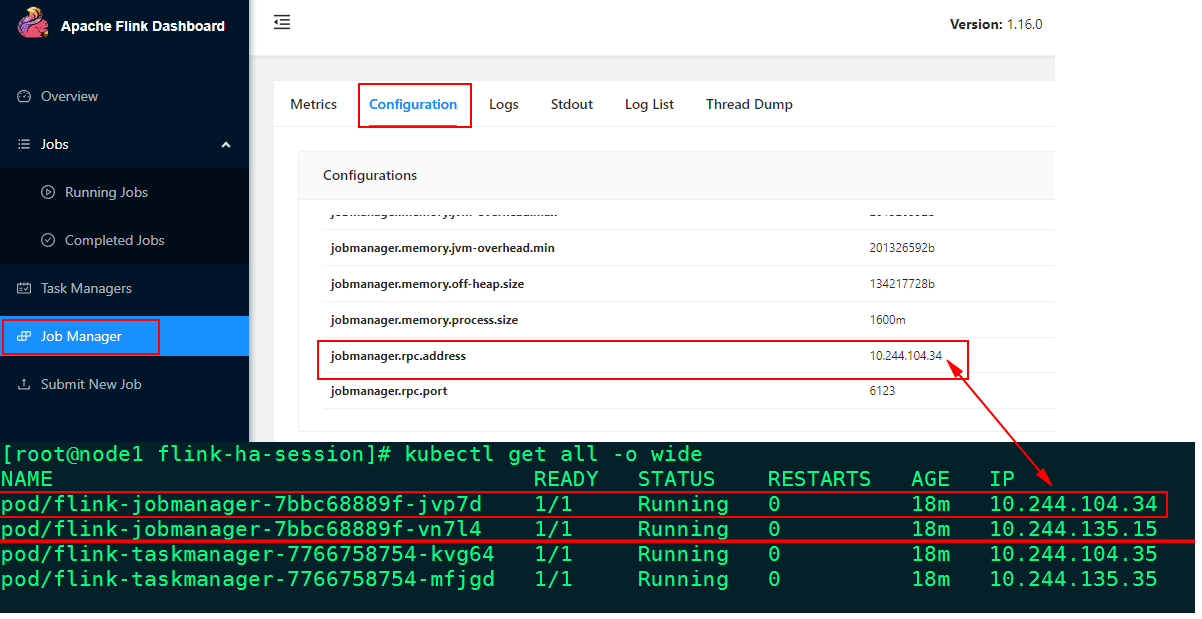
下面我们测试JobManager是否能正常切换。首先通过WebUI查看Active JobManager对应的IP信息:
然后在Kubernetes集群中根据这个IP找到对应的的Active JobManager节点并删除:
[root@node1 flink-ha-session]# kubectl delete pod flink-jobmanager-7bbc68889f-vn7l4
pod "flink-jobmanager-7bbc68889f-vn7l4" deleted
以上删除该Active JobManager对应的pod后,Kubernetes机制本身会尝试重启新的Pod,当然由于我们配置了Flink HA ,所以Kubernetes会在新启动的JobManager Pod与原来运行的Standby JobManager Pod中进行自动选主,有一定概率会选择原来一直运行的JobManager Pod当做Active JobManager。
重新查看Flink WebUI中JobManager IP:
通过以上验证我们发现原来备用的JobManager已经切换成Active JobManager。
注意:删除原来Activate JobManager后有可能将Kubernetes重新启动的JobManager选择为Active JobManager,可以尝试多次delete进行验证HA 切换。
1.8.1.1.2.5 任务提交与测试¶
这里基于命令行方式来进行任务提交,不再以WebUI方式提交Flink任务。
在任意能连接到Kubernetes集群的节点上上传Flink安装包,并解压,将打包好的Flink WordCountjar包进行上传,同时在node5节点上启动对应的Socket服务,执行如下命令提交Flink任务:
[root@node4 ~]# cd /software/flink-1.16.0/bin/
[root@node4 bin]# ./flink run -m 192.168.179.4:30081 -c com.mashibing.flinkjava.code.chapter_k8s.WordCount /software/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
向socket端口输入数据,通过kubectl logs + pods 方式查看对应的实时结果即可。
#在node5节点上启动socket 服务,并输入数据
[root@node5 ~]# nc -lk 9999
hello zhangsan
hello lisi
hello wangwu
#通过kubectl logs 查看对应的结果
[root@node1 flink-ha-session]# kubectl logs flink-taskmanager-7766758754-mfjgd
... ...
(zhangsan,1)
(hello,2)
(lisi,1)
(hello,3)
(wangwu,1)
1.8.1.1.2.6 停止集群¶
HA Session Cluster 集群停止时,在对应的目录下执行如下命令停止相应服务:
kubectl delete -f ./flink-configuration-configmap.yaml
kubectl delete -f ./jobmanager-cluster-role.yaml
kubectl delete -f ./jobmanager-rest-service.yaml
kubectl delete -f ./jobmanager-service.yaml
kubectl delete -f ./jobmanager-session-deployment-ha.yaml
kubectl delete -f ./taskmanager-session-deployment.yaml
注意:也可以进入对应yaml文件目录,直接执行 kubectl delete -f ./ 全部部署也可以。除了执行以上命令之外,还需要删除生成的额外的<cluster-id>-xxx configmap对象,命令如下:
#查看kubernetes 集群configmap 对象
[root@node1 flink-ha-session]# kubectl get configmap
NAME DATA AGE
kube-root-ca.crt 1 3d
myk8s-cluster-config-map 3 30m
#删除对应的configmap对象
[root@node1 flink-ha-session]# kubectl delete configmap myk8s-cluster-config-map
configmap "myk8s-cluster-config-map" deleted
1.8.1.2 Application Cluster部署¶
Application模式即一个作业使用单独的一个专用Flink集群,每个Flink作业的JobManager和TaskManager隔离。在Kubernetes 上部署Application Cluster集群时,与Session Cluster集群部署一样,一般至少包含三个组件:
- 运行JobManager的Deployment
- 运行TaskManager的Deployment
- 暴露JobManager上的REST和UI端口的Service
1.8.1.2.1 非HA Application Cluster部署及测试¶
1.8.1.2.1.1 准备deployment文件¶
- flink-configuration-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
parallelism.default: 2
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
- jobmanager-rest-service.yaml
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-rest
spec:
type: NodePort
ports:
- name: rest
port: 8081
targetPort: 8081
nodePort: 30081
selector:
app: flink
component: jobmanager
- jobmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123
- name: blob-server
port: 6124
- name: webui
port: 8081
selector:
app: flink
component: jobmanager
- jobmanager-application-deployment-non-ha.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: flink-jobmanager
spec:
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
restartPolicy: OnFailure
containers:
- name: jobmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
# 以下参数中 standalone-job、--job-classname 是固定的,后面一个参数是运行的Flink 主类,还可以继续跟参数,例如:"--input","/xxx/xx"
args: ["standalone-job", "--job-classname", "com.mashibing.flinkjava.code.chapter_k8s.WordCount"] # optional arguments: ["--job-id", "<job id>", "--fromSavepoint", "/path/to/savepoint", "--allowNonRestoredState"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
- name: job-artifacts-volume
mountPath: /opt/flink/usrlib #这里必须指定该路径,注意是usrlib ,Flink会从该路径读取用户自己的jar包
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: job-artifacts-volume
hostPath:
path: /software/flinkjar #将主类对应的jar包放入到该路径下(该路径要在k8s集群所有节点都要有才可以),可以自定义路径,直接会挂载到容器中
- name: localtime #同步本机时间到容器
hostPath:
path: /etc/localtime
type: ''
注意:本地/software/flinkjar 中需要上传运行Flink 主类对应的jar包,并且所有的Kubernetes节点都要有。最好采用nfs公共磁盘挂载。
- taskmanager-application-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
containers:
- name: taskmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
- name: job-artifacts-volume #这里必须指定该路径,注意是usrlib ,Flink会从该路径读取用户自己的jar包
mountPath: /opt/flink/usrlib
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: job-artifacts-volume #将主类对应的jar包放入到该路径下(该路径要在k8s集群所有节点都要有才可以),可以自定义路径,直接会挂载到容器中
hostPath:
path: /software/flinkjar
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
hostPath:
path: /etc/localtime
type: ''
1.8.1.2.1.2 部署yaml文件¶
由于Application模式部署即执行对应的Flink job,所以部署yaml文件前,需要在Kubernetes集群每台节点创建“/software/flinkjar”目录中上传对应的Flink jar包,然后在对应节点上启动socket服务:
[root@node5 ~]# nc -lk 9999
然后在对应的目录中执行如下命令,进行yaml文件部署
kubectl create -f flink-configuration-configmap.yaml
kubectl create -f jobmanager-application-deployment-non-ha.yaml
kubectl create -f jobmanager-rest-service.yaml
kubectl create -f taskmanager-application-deployment.yaml
注意:也可以进入对应yaml文件目录,直接执行 kubectl create -f ./ 全部部署也可以。
1.8.1.2.1.3 验证部署情况¶
[root@node1 flink-nonha-application]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/flink-jobmanager-r86z9 1/1 Running 0 8s
pod/flink-taskmanager-7b7b7d9758-7k7bc 1/1 Running 0 7s
pod/flink-taskmanager-7b7b7d9758-crkpw 1/1 Running 0 7s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flink-jobmanager-rest NodePort 10.103.201.10 <none> 8081:30081/TCP 8s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d22h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flink-taskmanager 2/2 2 2 7s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flink-taskmanager-7b7b7d9758 2 2 2 7s
NAME COMPLETIONS DURATION AGE
job.batch/flink-jobmanager 0/1 8s 8s
在浏览器输入:http://192.168.179.4:30081/即可访问Flink Application集群WebUI。浏览器中输入的ip可以是K8s集群中任意节点的IP。
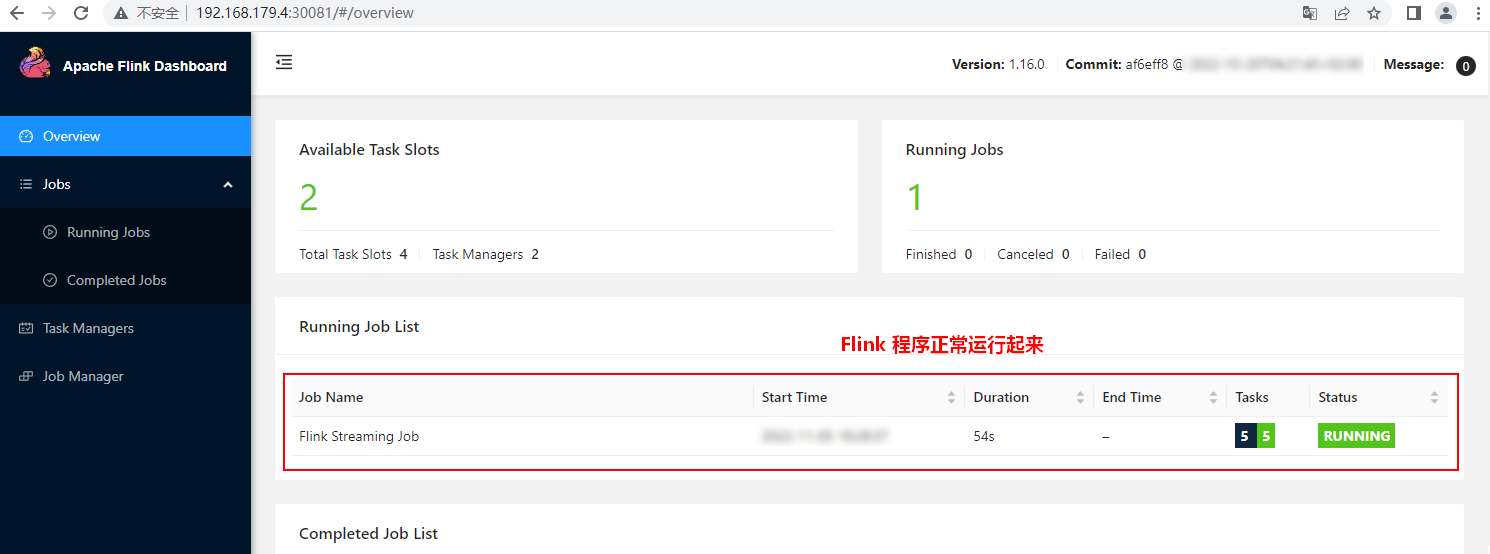
向node5 socket端口中输入数据并查询结果:
#向node5节点socket输入数据
[root@node5 ~]# nc -lk 9999
hello a
hello b
hello c
#查看结果
[root@node1 flink-nonha-application]# kubectl logs flink-taskmanager-7b7b7d9758-crkpw
... ...
1> (hello,1)
2> (a,1)
1> (hello,2)
1> (b,1)
1> (hello,3)
1> (c,1)
1.8.1.2.2 HA Application Cluster部署及测试¶
同样,基于Kubernetes Application Cluster 部署模式也支持HA模式。配置HA Application模式与非HA Application模式相比不再需要jobmanager-server.yaml文件。
1.8.1.2.2.1 准备deployment文件¶
- flink-configuration-configmap.yaml
该文件相比于非HA Session模式对应文件增加了以下行:
kubernetes.cluster-id: myk8s #给kubernets集群取个名字
high-availability: kubernetes #指定高可用模式
high-availability.storageDir: hdfs://mycluster/flink/recovery #指定元数据存储目录为hdfs路径
restart-strategy: fixed-delay #指定重启策略
restart-strategy.fixed-delay.attempts: 10 #指定重启尝试次数
以上配置使用kubernetes来进行协调FlinkHA,部署相应flink-configuration-configmap.yaml文件后在Kubernetes中会额外生成<cluster-id>-xxx对应的configmap对象,此对象记录Flink 集群中提交的job元数据。完整的flink-configuration-configmap.yaml文件如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
parallelism.default: 2
kubernetes.cluster-id: myk8s #给kubernets集群取个名字
high-availability: kubernetes #指定高可用模式
high-availability.storageDir: hdfs://mycluster/flink/recovery #指定元数据存储目录为hdfs路径
restart-strategy: fixed-delay #指定重启策略
restart-strategy.fixed-delay.attempts: 10 #指定重启尝试次数
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
- jobmanager-rest-service.yaml
改文件与非HA Application模式部署对应的文件一样。
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-rest
spec:
type: NodePort
ports:
- name: rest
port: 8081
targetPort: 8081
nodePort: 30081
selector:
app: flink
component: jobmanager
- jobmanager-cluster-role.yaml
在k8s中是基于角色授权的,创建用户时需要绑定对应的角色,在JobManager HA 部署案例中需要操作对应的配置ConfigMap文件。这里通过jobmanager-cluster-role.yaml创建一个ClusterRole,然后再创建用户,将用户绑定到该集群角色,拥有对ConfigMap操作权限。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: configmaps-role #创建ClusterRole的名称
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["configmaps"] #指定操作的资源为configmaps
verbs: ["create", "edit", "delete","get", "watch", "list","update"] #指定操作的权限
以上创建完成,再创建一个用户叫flink-service-account,后续将用户绑定到该角色。
kubectl create serviceaccount flink-service-account
把flink-service-account用户绑定到集群角色:
kubectl create clusterrolebinding flink-role-binding-serviceaccount --clusterrole=configmaps-role --serviceaccount=default:flink-service-account
- jobmanager-application-deployment-ha.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: flink-jobmanager
spec:
#这里配置2个副本
parallelism: 2 # Set the value to greater than 1 to start standby JobManagers
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
hostAliases: #向容器/etc/hosts中加入ip与节点名称映射,pod找HDFS集群时需要使用
- ip: 192.168.179.4
hostnames:
- "node1"
- ip: 192.168.179.5
hostnames:
- "node2"
- ip: 192.168.179.6
hostnames:
- "node3"
- ip: 192.168.179.7
hostnames:
- "node4"
- ip: 192.168.179.8
hostnames:
- "node5"
restartPolicy: OnFailure
containers:
- name: jobmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: HADOOP_CLASSPATH #这里由于在flink pod内使用到HDFS ,需要把宿主机的HDFS配置文件挂载进来,并配置HADOOP_CLASSPATH环境变量,可以通过在宿主机执行echo `hadoop classpath`来参考这里导入的路径,记得要把Hadoop路径改成挂载到Pod中的路径
value: /opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
# The following args overwrite the value of jobmanager.rpc.address configured in the configuration config map to POD_IP.
# 以下参数中 standalone-job、--job-classname 是固定的,后面一个参数是运行的Flink 主类,还可以继续跟参数,例如:"--input","/xxx/xx"
args: ["standalone-job","--host","$(POD_IP)", "--job-classname", "com.mashibing.flinkjava.code.chapter_k8s.WordCount"] # optional arguments: ["--job-id", "<job id>", "--fromSavepoint", "/path/to/savepoint", "--allowNonRestoredState"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
- name: job-artifacts-volume
mountPath: /opt/flink/usrlib #这里必须指定该路径,注意是usrlib ,Flink会从该路径读取用户自己的jar包
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
mountPath: /opt/hadoop
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
serviceAccountName: flink-service-account # Service account which has the permissions to create, edit, delete ConfigMaps
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: job-artifacts-volume
hostPath:
path: /software/flinkjar #将主类对应的jar包放入到该路径下(该路径要在k8s集群所有节点都要有才可以),可以自定义路径,直接会挂载到容器中
- name: localtime #同步本机时间到容器
hostPath:
path: /etc/localtime
type: ''
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
hostPath:
path: /software/hadoop-3.3.4
type: ''
- taskmanager-application-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
hostAliases: #向容器/etc/hosts中加入ip与节点名称映射,pod找HDFS集群时需要使用
- ip: 192.168.179.4
hostnames:
- "node1"
- ip: 192.168.179.5
hostnames:
- "node2"
- ip: 192.168.179.6
hostnames:
- "node3"
- ip: 192.168.179.7
hostnames:
- "node4"
- ip: 192.168.179.8
hostnames:
- "node5"
containers:
- name: taskmanager
image: flink:1.16.0-scala_2.12-java8 #指定Flink的镜像,可以从https://hub.docker.com/ 网站上查找
env:
- name: HADOOP_CLASSPATH #这里由于在flink pod内使用到HDFS ,需要把宿主机的HDFS配置文件挂载进来,并配置HADOOP_CLASSPATH环境变量,可以通过在宿主机执行echo `hadoop classpath`来参考这里导入的路径,记得要把Hadoop路径改成挂载到Pod中的路径
value: /opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
mountPath: /etc/localtime
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
mountPath: /opt/hadoop
- name: job-artifacts-volume #这里必须指定该路径,注意是usrlib ,Flink会从该路径读取用户自己的jar包
mountPath: /opt/flink/usrlib
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
serviceAccountName: flink-service-account #指定seviceAccountName 用户名
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
- name: job-artifacts-volume #将主类对应的jar包放入到该路径下(该路径要在k8s集群所有节点都要有才可以),可以自定义路径,直接会挂载到容器中
hostPath:
path: /software/flinkjar
- name: localtime #挂载localtime文件,使容器时间与宿主机一致
hostPath:
path: /etc/localtime
type: ''
- name: hadoop-conf #将宿主机中的配置好的hadoop的安装包挂载到容器
hostPath:
path: /software/hadoop-3.3.4
type: ''
注意:关于Flink的镜像可以从https://hub.docker.com/网站中搜索下载。
由于在flink pod内使用到HDFS ,需要把宿主机的HDFS配置文件挂到Flink JobManager和TaskManager中并配置HADOOP_CLASSPATH环境变量,可以通过在宿主机执行echo hadoop classpath来参考HADOOP_CLASSPATH环境变量对应的value值路径,记得要把Hadoop路径改成挂载到Pod中的路径。
以上配置文件可以从资料“flink-ha-application.zip”中获取。
1.8.1.2.2.2 部署yaml文件¶
由于HA模式使用到了HDFS集群,所以这里应该首先启动HDFS集群然后再部署对应的yaml文件。
#启动zookeeper
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
#启动HDFS集群
[root@node1 ~]# start-all.sh
部署之前记得执行上一小节中创建用户与绑定用户到角色命令,如果执行过不必重复创建执行。
kubectl create serviceaccount flink-service-account
kubectl create clusterrolebinding flink-role-binding-serviceaccount --clusterrole=configmaps-role --serviceaccount=default:flink-service-account
在对应的目录中执行如下命令,部署yaml文件
kubectl create -f ./flink-configuration-configmap.yaml
kubectl create -f ./jobmanager-application-deployment-ha.yaml
kubectl create -f ./jobmanager-cluster-role.yaml
kubectl create -f ./jobmanager-rest-service.yaml
kubectl create -f ./taskmanager-application-deployment.yaml
注意:也可以进入对应yaml文件目录,直接执行 kubectl create -f ./ 全部部署也可以。
1.8.1.2.2.3 验证部署情况¶
[root@node1 flink-ha-application]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/flink-jobmanager-bbp97 1/1 Running 0 60s
pod/flink-jobmanager-xvjts 1/1 Running 0 60s
pod/flink-taskmanager-58685d568f-7lhhg 1/1 Running 0 60s
pod/flink-taskmanager-58685d568f-nj6nf 1/1 Running 0 60s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flink-jobmanager-rest NodePort 10.97.107.147 <none> 8081:30081/TCP 60s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d1h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flink-taskmanager 2/2 2 2 60s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flink-taskmanager-58685d568f 2 2 2 60s
NAME COMPLETIONS DURATION AGE
job.batch/flink-jobmanager 0/1 of 2 60s 60s
在浏览器输入:http://192.168.179.4:30081/即可访问Flink Application集群WebUI,可以看到对应主类的Flink job已经处于运行状态。

1.8.1.2.2.4 HA高可用验证¶
HA验证方式与HA Session Cluster 部署方式验证方式一样。可以参考HA Session Cluster 部署方式HA高可用验证。
1.8.2 Native Kubernetes部署¶
Flink的Native Kubernetes集成允许我们直接将Flink部署到正在运行的Kubernetes集群上,Flink能够根据所需的资源通过与Kubernetes 集群通信动态分配和取消分配taskmanager,其部署原理图如下:

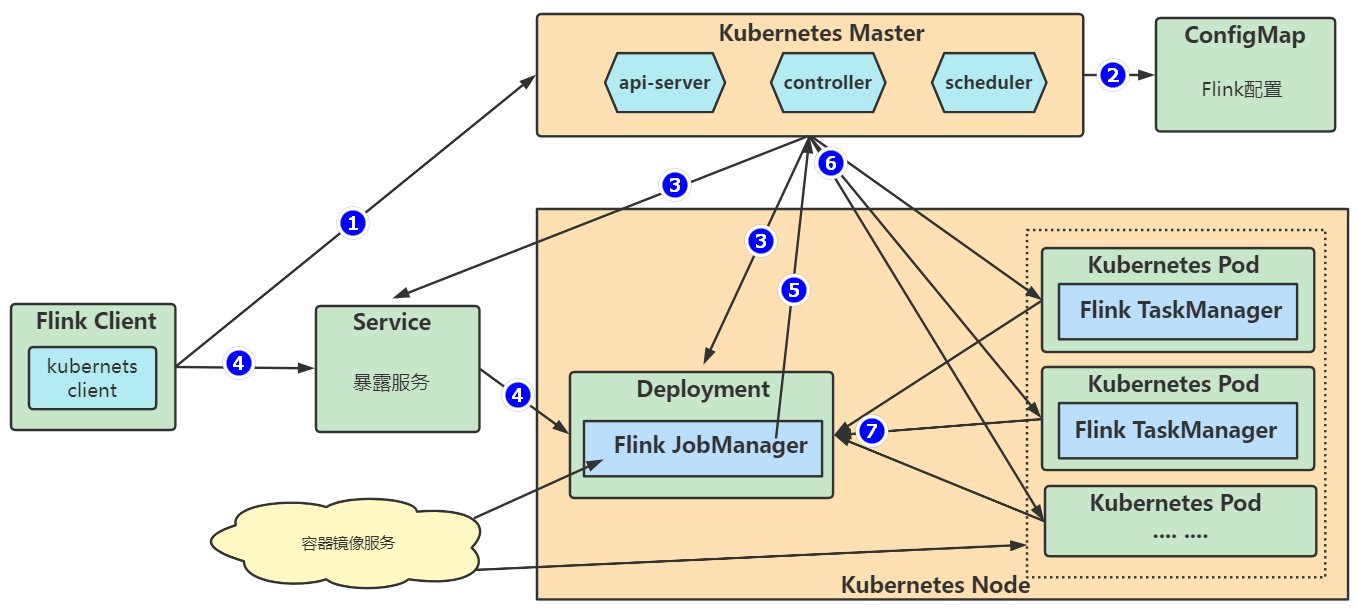
Flink Native kubernetes集成需要一个Kubernetes集群,并且Kubernetes版本需要大于等于1.9 版本,Flink Native kubernetes支持Flink Client 创建Session Cluster和Application Cluster集群部署并进行任务提交,也支持对应HA的任务执行,但是需要自定义pod的yaml资源清单文件实现,这与基于Kubernetes中Session Cluster和Application Cluster类似,这里不再两种模式的HA方式,具体HA方式参考Kubernetes部署。
Flink Native kubernetes的Session Cluster和Application Cluster集群部署两种方式都需要指定具备RBAC(Role-based access control)权限的serviceaccount,以便创建、删除集群内的Pod。
下面首先创建serviceaccount,并绑定到edit的ClusterRole角色,方便创建和删除集群pod。
1) 创建名称为flink的serviceaccount
#创建 serviceaccount ,名称为flink
[root@node1 ~]# kubectl create serviceaccount flink
查看创建好的seviceaccount:
[root@node1 ~]# kubectl get serviceaccount
NAME SECRETS AGE
default 0 5d21h
flink 0 7m26s
2) 为serviceaccount flink绑定角色
#这里创建clusterrolebinding名称为flink-role-binding-flink,绑定的serviceaccount 名称是flink,绑定到的clusterrole角色为edit
[root@node1 ~]# kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink
查看创建的clusterrolebinding:
[root@node1 ~]# kubectl get clusterrolebinding |grep flink-role-binding-flink
1.8.2.1 Session Cluster模式¶
Session Cluster模式通过Flink Client连接Kubernetes集群进行创建,Flink Client必须在Kubernetes集群内的某台节点,否则Flink Client 连接不上Kubernetes集群。这里选择node3节点当做Flink客户端,将Flink安装包上传至node3节点,并解压。
#将Flink安装包上传到/software目录下,并解压
[root@node3 ~]# cd /software/
[root@node3 software]# tar -zxvf ./flink-1.16.0-bin-scala_2.12.tgz
通过以下步骤创建Session Cluster并提交任务、操作任务。
1.8.2.1.1 启动Session集群¶
[root@node3 ~]# cd /software/flink-1.16.0/bin/
[root@node3 bin]#./kubernetes-session.sh \
-Dkubernetes.container.image=flink:1.16.0-scala_2.12-java8\
-Dkubernetes.jobmanager.service-account=flink \
-Dkubernetes.cluster-id=my-first-flink-cluster\
-Dkubernetes.rest-service.exposed.type=NodePort\
-Dtaskmanager.memory.process.size=1024m \
-Dkubernetes.taskmanager.cpu=1 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dresourcemanager.taskmanager-timeout=60000
以上参数解释如下:
- kubernetes.container.image:指定Flink image镜像。
- kubernetes.jobmanager.service-account:指定操作的serviceaccount名称
- kubernetes.cluster-id:指定Flink Session Cluster对应Kubernetes集群的id,名字随意,指定后在Kubernetes集群中会有对应名称的Deployment。
- kubernetes.rest-service.exposed.type:指定创建的JobManager rest ui服务对外暴露服务的方式。
- taskmanager.memory.process.size:指定每个TaskManager使用的总内存。
- kubernetes.taskmanager.cpu:指定TaskManager使用的cup个数,默认为1。
- taskmanager.numberOfTaskSlots:指定TaskManager 对应的slot个数,默认为1。
- resourcemanager.taskmanager-timeout:Flink默认会自动取消空闲的TaskManager以避免浪费资源,一旦对应的TaskManager Pod停止,就不能再查看对应Pod的日志,可以设置该参数指定空闲的TaskManager多久可以被销毁,默认30000,即30s。
更多参数可以参考Flink官网配置:
https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#kubernetes
此外,以上flink:1.16.0-scala_2.12-java8 镜像下载需要科学上网工具,如何下载不下来也可以直接导入资料中的“flink1.16.0-scala_2.12-java8.tar”镜像,方法如下:
#将flink1.16.0-scala_2.12-java8.tar上传到对应节点,这里上传至Master节点,然后执行如下命令导入镜像
[root@node1 ~]# docker load -i /software/flink1.16.0-scala_2.12-java8.tar
f4a670ac65b6: Loading layer [==================================================>] 80.31MB/80.31MB
aa2e51f5ab8a: Loading layer [==================================================>] 36.6MB/36.6MB
9b110457aa6d: Loading layer [==================================================>] 108.8MB/108.8MB
6428f4fb9d66: Loading layer [==================================================>] 2.56kB/2.56kB
2da66d05adf1: Loading layer [==================================================>] 11.8MB/11.8MB
2d441efefbd5: Loading layer [==================================================>] 2.3MB/2.3MB
4463bbe0b1a3: Loading layer [==================================================>] 3.254MB/3.254MB
0236f57a147f: Loading layer [==================================================>] 2.56kB/2.56kB
3d6f741552ee: Loading layer [==================================================>] 520.8MB/520.8MB
eb617b6c57b4: Loading layer [==================================================>] 7.168kB/7.168kB
Loaded image: flink:1.16.0-scala_2.12-java8
#查看导入的镜像
[root@node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flink 1.16.0-scala_2.12-java8 584a51fe68ac 10 days ago 759MB
启动Kubernetes Session Cluster 集群后,可以看到打印出外网访问的IP及端口,可以登录检查启动的Session集群是否正常。

1.8.2.1.2 停止Session Cluster集群¶
当启动Session Cluster后,在Kubernetes集群中会有名称与“kubernetes.cluster-id”参数配置一样的deployment,查看方式如下:
[root@node1 ~]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/my-first-flink-cluster-577f9d9d9b-wk9c7 1/1 Running 0 6m10s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5d21h
service/my-first-flink-cluster ClusterIP None <none> 6123/TCP,6124/TCP 6m10s
service/my-first-flink-cluster-rest NodePort 10.101.64.92 <none> 8081:32755/TCP 6m10s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-first-flink-cluster 1/1 1 1 6m10s
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-first-flink-cluster-577f9d9d9b 1 1 1 6m10s
停止对应的Session Cluster集群有两种方式,一种是通过Kubernetes命令停止对应的Deployment,另一种是通过Flink Client停止。
- Kubernetes命令停止Session Cluster集群:
[root@node1 ~]# kubectl delete deployment.apps/my-first-flink-cluster
- Flink Client停止Session Cluster集群:
[root@node3 bin]# echo 'stop' | ./kubernetes-session.sh -Dkubernetes.cluster-id=my-first-flink-cluster -Dexecution.attached=true
1.8.2.1.3 提交任务¶
这里向启动的Flink Session Cluster 集群中提交任务,任务与之前Flink测试任务一样:读取node5节点上socket 9999 端口数据实时统计WordCount。按照以下步骤来进行任务提交:
1) 在node5节点上启动Socket服务。
[root@node5 ~]# nc -lk 9999
2) 在node3节点上传用户打好的jar包,放入/software/flinkjar目录中
[root@node3 ~]# mkdir -p /software/flinkjar
[root@node3 flinkjar]# ls
FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
3) 执行如下命令提交任务并测试:
[root@node3 ~]# cd /software/flink-1.16.0/bin/
[root@node3 bin]# ./flink run \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-c com.mashibing.flinkjava.code.chapter_k8s.WordCount \
/software/flinkjar/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar

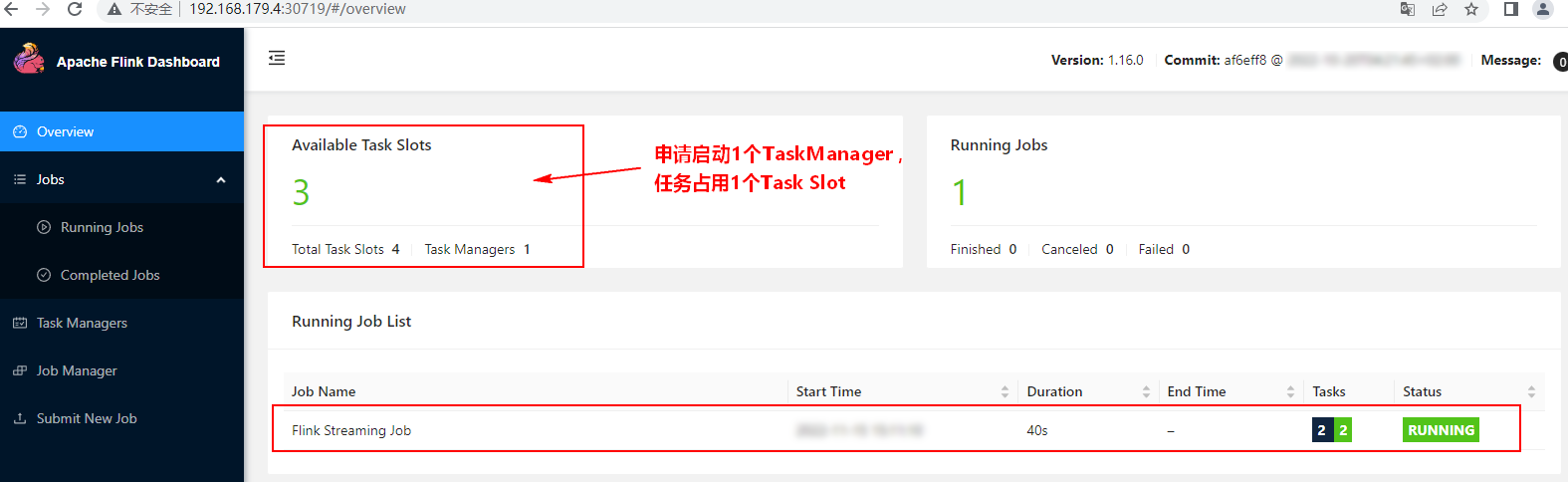
session集群中提交任务需要指定--target为kubernetes-session即可,另外可以在提交任务时指定参数-d ,在向Kubernetes中Flink Session Cluster集群提交任务后退出客户端。
[root@node3 bin]# ./flink run -d \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-c com.mashibing.flinkjava.code.chapter_k8s.WordCount \
/software/flinkjar/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
可以在node5节点socket中输入以下数据:
[root@node5 ~]# nc -lk 9999
hello a
hello b
hello c
查看stdout结果需要使用kubernetes集群命令来查询:
[root@node1 software]# kubectl logs my-first-flink-cluster-taskmanager-1-1
... ....
(hello,1)
(a,1)
(hello,2)
(b,1)
(hello,3)
(c,1)
1.8.2.1.4 测试资源申请与释放¶
默认创建Flink Session Cluster集群指定了每个TaskManager 具备1core和4个slot,当向Flink Session Cluster 集群中提交一个任务时(默认1个并行度)会使用1个slot,当提交多次Flink任务时可以看到FlinkSession Cluster集群可以动态申请TaskManager

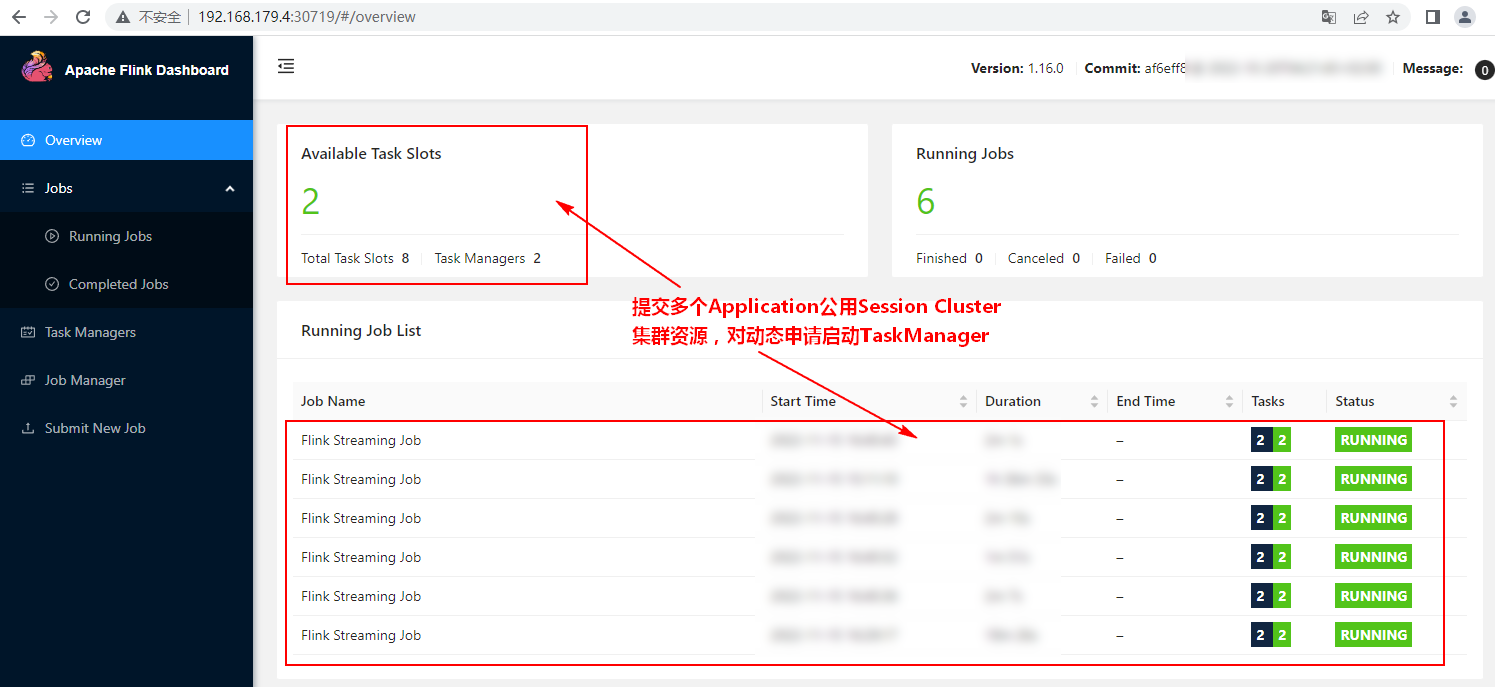
通过以上测试会发现,当提交多个Flink 任务时,这些任务共用一个Flink Session Cluster集群,每提交一个Flink任务会分配1个slot,当Session Cluster Slot不够时Kubernetes集群会动态启动新的TaskManager。查看集群中提交的任务:
[root@node3 bin]# ./flink list \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster
可以通过以下命令取消对应任务执行:
./flink cancel \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
任务id
当把集群任务一个个取消后,集群TaskManager会经过“resourcemanager.taskmanager-timeout”参数指定的时间后动态释放以便节省资源,在创建Flink Session Cluster集群时该参数指定60000ms ,即1分钟,Kubernetes集群会在1分钟后自动删除空闲的TaskManager。

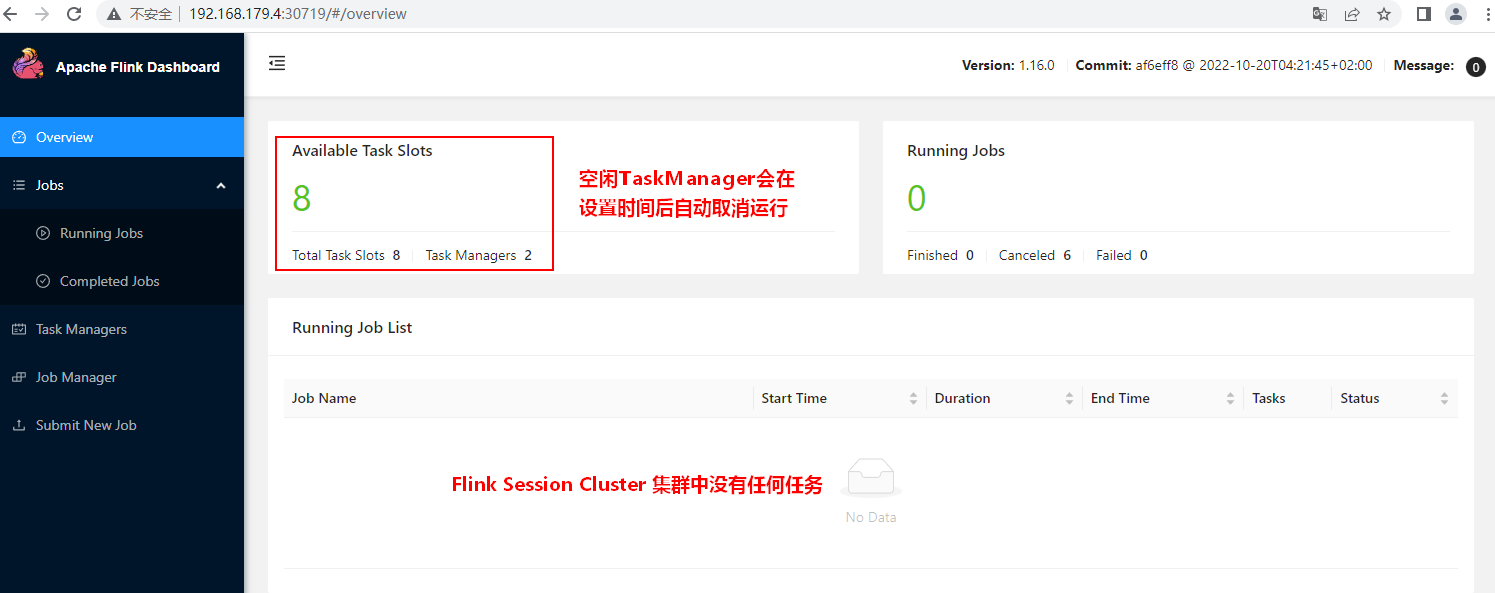
1.8.2.2 Application Cluster模式¶
在生产环境中,建议基于Application Cluster集群来部署Flink应用程序,因为这些模式为应用程序提供了更好的隔离。Flink基于Native Kubernetes 同样也支持Application Cluster模式,在Flink客户端指定对应的命令可以直接为每个Flink Application 创建一个单独的集群。Flink Application Cluster 中通过Flink客户端提交Flink任务需要自己提前构建flink的镜像,将用户对应执行的jar包上传到镜像内,目前官方没有提供外部指定参数方式来指定用户jar包。
1.8.2.2.1 Harbor构建私有镜像仓库¶
在企业中使用Kubernetes时,为了方便下载和管理镜像一般都会构建本地的私有镜像仓库。Harbor正是一个用于存储镜像的企业级Registry服务,我们可以通过Harbor来存储容器镜像构建企业本地的镜像仓库。
这里我们选择一台Kubernetes集群外的一台节点搭建Harbor,当然也可以选择Kubernetes集群内的一台节点。
| 节点IP | 节点名称 | Harbor |
|---|---|---|
| 192.168.179.4 | node1 | |
| 192.168.179.5 | node2 | |
| 192.168.179.6 | node3 | |
| 192.168.179.7 | node4 | ★ |
| 192.168.179.8 | node5 |
1) 安装docker
#准备docker-ce对应的repo文件
[root@node4 ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
#安装docker-ce
[root@node4 ~]# yum -y install docker-ce
#设置docker开机启动,并启动docker
[root@node4 ~]# systemctl enable docker
[root@node4 ~]# systemctl start docker
2) 安装docker-compose
后续需要docker-compose编排工具进行harbor的启停,这里需要安装docker-compose。
#下载docker-compose的二进制文件,改文件如果下载不下来可以参照资料中“docker-compose-Linux-x86_64”文件
[root@node4 ~]# wget https://github.com/docker/compose/releases/download/1.25.0/docker-compose-Linux-x86_64
#移动二进制文件到/usr/bin目录,并更名为docker-compose
[root@node4 ~]# mv docker-compose-Linux-x86_64 /usr/bin/docker-compose
# 为二进制文件添加可执行权限
chmod +x /usr/bin/docker-compose
#以上操作完成后,查看docker-compse版本
[root@node4 ~]# docker-compose version
docker-compose version 1.25.0, build 0a186604
docker-py version: 4.1.0
CPython version: 3.7.4
OpenSSL version: OpenSSL 1.1.0l 10 Sep 2019
- 获取Harbor安装文件并解压
#下载harbor离线安装包,如果下载不下来参考资料中“harbor-offline-installer-v2.5.1.tgz”文件
[root@node4 ~]# wget https://github.com/goharbor/harbor/releases/download/v2.5.1/harbor-offline-installer-v2.5.1.tgz
#解压下载好的安装包
[root@node4 ~]# tar -zxvf ./harbor-offline-installer-v2.5.1.tgz
- 修改Harbor配置文件
搭建Harbor本地镜像仓库时,可以使用ssl安全访问私有镜像仓库,但是Flink Native Kubernetes中Application模式提交任务下载镜像默认是https方式访问仓库地址,所以这里需要给Harbor配置ssl证书,具体证书参照资料“6864844_kubemsb.com_nginx.zip”文件。
- 准备Harbor的harbor.yml配置文件:
[root@node4 ~]# cd harbor
[root@node4 harbor]# mv harbor.yml.tmpl harbor.yml
#将资料中“6864844_kubemsb.com_nginx.zip”压缩文件进行解压,然后把证书的pem文件和key文件上传到该目录
[root@node4 harbor]# ls /root/harbor
6864844_kubemsb.com.key 6864844_kubemsb.com.pem
- 修改harbor.yml文件内容如下:
# Configuration file of Harbor
# The IP address or hostname to access admin UI and registry service.
# DO NOT use localhost or 127.0.0.1, because Harbor needs to be accessed by external clients.
hostname: www.kubemsb.com
# http related config
http:
# port for http, default is 80. If https enabled, this port will redirect to https port
port: 80
# https related config
https:
# https port for harbor, default is 443
port: 443
# The path of cert and key files for nginx
certificate: /root/harbor/6864844_kubemsb.com.pem
private_key: /root/harbor/6864844_kubemsb.com.key
# # Uncomment following will enable tls communication between all harbor components
# internal_tls:
# # set enabled to true means internal tls is enabled
# enabled: true
# # put your cert and key files on dir
# dir: /etc/harbor/tls/internal
# Uncomment external_url if you want to enable external proxy
# And when it enabled the hostname will no longer used
# external_url: https://reg.mydomain.com:8433
# The initial password of Harbor admin
# It only works in first time to install harbor
# Remember Change the admin password from UI after launching Harbor.
harbor_admin_password: 123456
... ...
注意harbor.yml文件中只需要配置hostname、certificate、private_key、harbor_admin_password即可。
- 执行预备脚本并安装
#执行预备脚本,检查安装所需镜像
[root@node4 harbor]# ./prepare
prepare base dir is set to /root/harbor
Clearing the configuration file: /config/portal/nginx.conf
Clearing the configuration file: /config/log/logrotate.conf
Clearing the configuration file: /config/log/rsyslog_docker.conf
Clearing the configuration file: /config/nginx/nginx.conf
Clearing the configuration file: /config/core/env
Clearing the configuration file: /config/core/app.conf
Clearing the configuration file: /config/registry/passwd
Clearing the configuration file: /config/registry/config.yml
Clearing the configuration file: /config/registryctl/env
Clearing the configuration file: /config/registryctl/config.yml
Clearing the configuration file: /config/db/env
Clearing the configuration file: /config/jobservice/env
Clearing the configuration file: /config/jobservice/config.yml
Generated configuration file: /config/portal/nginx.conf
Generated configuration file: /config/log/logrotate.conf
Generated configuration file: /config/log/rsyslog_docker.conf
Generated configuration file: /config/nginx/nginx.conf
Generated configuration file: /config/core/env
Generated configuration file: /config/core/app.conf
Generated configuration file: /config/registry/config.yml
Generated configuration file: /config/registryctl/env
Generated configuration file: /config/registryctl/config.yml
Generated configuration file: /config/db/env
Generated configuration file: /config/jobservice/env
Generated configuration file: /config/jobservice/config.yml
loaded secret from file: /data/secret/keys/secretkey
Generated configuration file: /compose_location/docker-compose.yml
Clean up the input dir
#执行安装脚本
[root@node4 harbor]# ./install.sh
...
[Step 5]: starting Harbor ...
Creating network "harbor_harbor" with the default driver
Creating harbor-log ... done
Creating registryctl ... done
Creating harbor-db ... done
Creating registry ... done
Creating harbor-portal ... done
Creating redis ... done
Creating harbor-core ... done
Creating nginx ... done
Creating harbor-jobservice ... done
✔ ----Harbor has been installed and started successfully.----
- 验证Harbor情况
#使用docker ps 命令检查是否是运行9个镜像,如下
[root@node4 harbor]# docker ps
CONTAINER ID IMAGE a81fbd05dc13 goharbor/harbor-jobservice:v2.5.1 c374cf3d741a goharbor/nginx-photon:v2.5.1
152c165b0804 goharbor/harbor-core:v2.5.1 4e48926df8b0 goharbor/redis-photon:v2.5.1 6d514441a600 goharbor/harbor-db:v2.5.1 0a170f716955 goharbor/registry-photon:v2.5.1 a8d99c7b2421 goharbor/harbor-portal:v2.5.1 2b808612f108 goharbor/harbor-registryctl:v2.5.1 69c2c7818e6a goharbor/harbor-log:v2.5.1
注意:安装harbor后,查看对应的 docker images 是否是9个,不是9个需要重新启动harbor。重启Harbor的命令如下:
[root@node4 harbor]# cd /root/harbor
#停止harbor服务
[root@node4 harbor]# docker-compose down
#启动harbor服务
[root@node4 harbor]# docker-compose up -d
- 配置Kubernetes节点及harbor节点访问harbor服务
后续Kubernetes各个节点(包括harbor节点本身)需要连接Harbor上传或者下载镜像,所以这里配置各个节点访问harbor。配置各个节点hosts文件配置www.kubemsb.com的映射:
#这里在node1-node4各个节点修改/etc/hosts文件,加入以下配置
192.168.179.7 www.kubemsb.com
kubernetes集群所有节点配置harbor仓库(包括harbor节点本身也要配置):
#kubernetes 集群各个节点配置/etc/docker/daemon.json文件,追加"insecure-registries": ["https://www.kubemsb.com"]
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"insecure-registries": ["https://www.kubemsb.com"]
}
#harbor节点配置 /etc/docker/daemon.json文件
{
"insecure-registries": ["https://www.kubemsb.com"]
}
以上配置完成后,配置的每台节点需要重启docker,重点需要注意harbor节点docker重启后是否是对应有9个image,如果不是9个需要使用docker-compose down 停止harbor集群后再次使用命令docker-compse up -d 启动。
systemctl restart docker
检查每个节点是否能正常连接Harbor,这里每台节点连接harbor前必须需要执行如下命令登录下harbor私有镜像仓库。
docker login www.kubemsb.com
输入用户:admin
输入密码:123456
- 访问Harbor UI界面
在window本地“C:\Windows\System32\drivers\etc\hosts”中加入对应的映射。
192.168.179.7 www.kubemsb.com
然后浏览器访问harbor(只能是域名访问,不能IP访问),用户名为admin,密码为配置的123456。
- 测试Harbor
使用docker下载nginx镜像并上传至harbor,然后通过docker从harbor中下载该上传镜像,测试是否能正常从harbor下载存储管理的镜像。具体操作如下:
#docker 下载nginx镜像
[root@node1 ~]# docker pull nginx:1.15-alpine
#检查镜像
[root@node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.15-alpine dd025cdfe837 3 years ago 16.1MB
#对nginx镜像进行标记打tag
[root@node1 ~]# docker tag nginx:1.15-alpine www.kubemsb.com/library/nginx:v1
#检查镜像
[root@node1 software]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.15-alpine dd025cdfe837 3 years ago 16.1MB
www.kubemsb.com/library/nginx v1 dd025cdfe837 3 years ago 16.1MB
#推送本地镜像到harbor镜像仓库
[root@node1 ~]# docker push www.kubemsb.com/library/nginx:v1
将本地镜像推送到harbor镜像仓库后,可以通过WebUI查看对应内容:

可以在本地任何一台节点上从Harbor镜像仓库中下载镜像到本地:
[root@node2 ~]# docker pull www.kubemsb.com/library/nginx:v1
1.8.2.2.2 制作Flink 镜像¶
Native kubernetes 中Flink Application Cluster 模式提交一个任务会直接执行对应Flink任务,该任务独立生成并使用Flink Application Cluster,Flink 客户端提交命令时没有提供指定外部用户jar包的指令,所以这里需要将用户的jar包打入到flink镜像内,然后在客户端提交任务时直接指定对应的镜像即可。
这里通过Dockerflie将用户jar包打入到镜像内,并将制作好的镜像上传到harbor镜像服务器中,方便后续使用。这里可以在Kubernetes任意一台节点制作Flink镜像。
1) 使用docker下载flink镜像
[root@node1 ~]# docker pull flink:1.16.0-scala_2.12-java8
2) 准备Dockerflie
#在node1节点创建myflink目录
[root@node1 ~]# mkdir myflink && cd myflink
#将用户jar包上传至myflink目录下,方便后续制作镜像
[root@node1 myflink]# ls
FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
#创建Dockerfile,写入如下内容
FROM flink:1.16.0-scala_2.12-java8
RUN mkdir -p $FLINK_HOME/usrlib
COPY ./FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar $FLINK_HOME/usrlib/
注意:以上构建的镜像中是将用户的jar包上传到镜像中的$FLINK_HOME/usrlib中,即/opt/flink/usrlib中。
3) 构建docker镜像
#构建docker 镜像
[root@node1 myflink]# docker build -t myflink:v1 .
#查看制作好的镜像
[root@node1 myflink]# docker images
REPOSITORY TAG
myflink v1
4) 上传docker镜像到Harbor服务器
#对制作好的myflink:v1镜像打标签
[root@node1 myflink]# docker tag myflink:v1 www.kubemsb.com/library/myflink:v1
#查看镜像
[root@node1 myflink]# docker images
REPOSITORY TAG
www.kubemsb.com/library/myflink v1
myflink v1
#将镜像上传至harbor服务器
[root@node1 myflink]# docker push www.kubemsb.com/library/myflink:v1
通过Harbor WebUI检查对应的镜像:

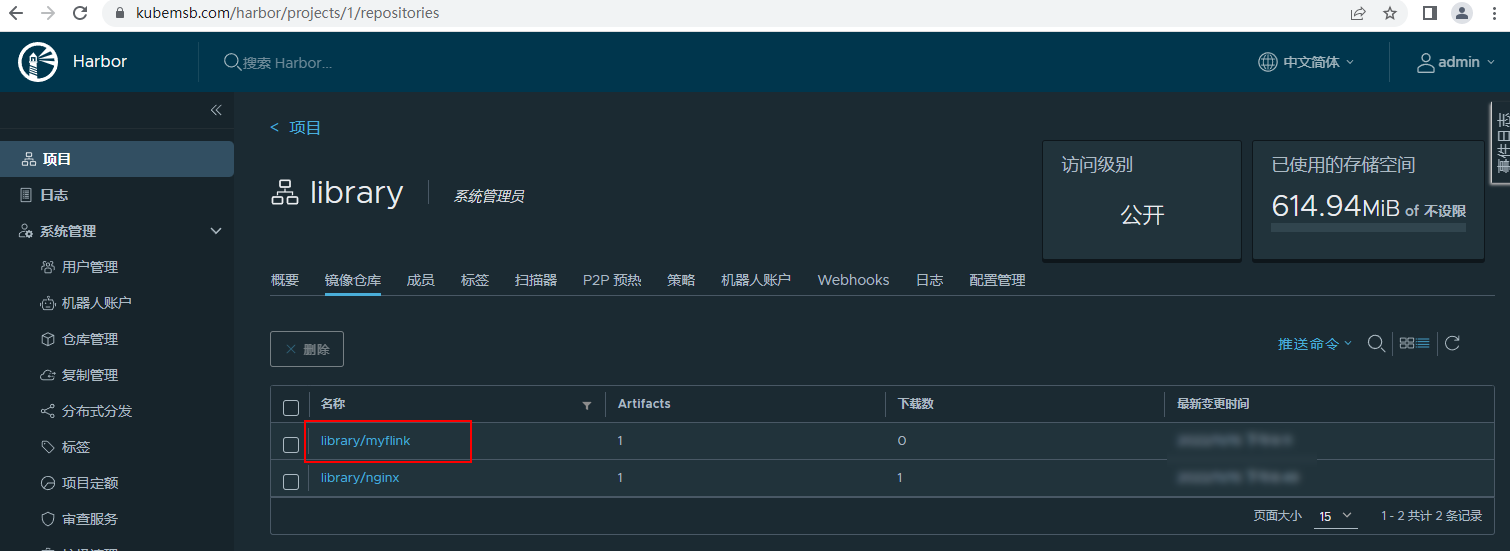
1.8.2.2.3 提交Flink 任务及测试¶
Flink Application Cluster模式提交任务后当前任务独自使用集群,Application Cluster集群启动同时任务也就运行了,所以需要在node5节点中启动socket服务,然后再执行任务提交明林,命令如下:
[root@node3 ~]# cd /software/flink-1.16.0/bin/
[root@node3 ~]# ./flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=www.kubemsb.com/library/myflink:v1 \
-Dkubernetes.rest-service.exposed.type=NodePort\
-Dkubernetes.jobmanager.service-account=flink\
-Dtaskmanager.memory.process.size=1024m \
-Dkubernetes.taskmanager.cpu=1 \
-Dtaskmanager.numberOfTaskSlots=4 \
-c com.mashibing.flinkjava.code.chapter_k8s.WordCount \
local:///opt/flink/usrlib/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
以上命令中--target 指定为kubernetes-application即是Application模式提交任务,其他参数与Session Cluster模式一样。
提交任务之后,可以看到对应的WebUI 的IP及端口,通过浏览器查看WebUI,可以看到一个Flink任务独立使用单独集群:

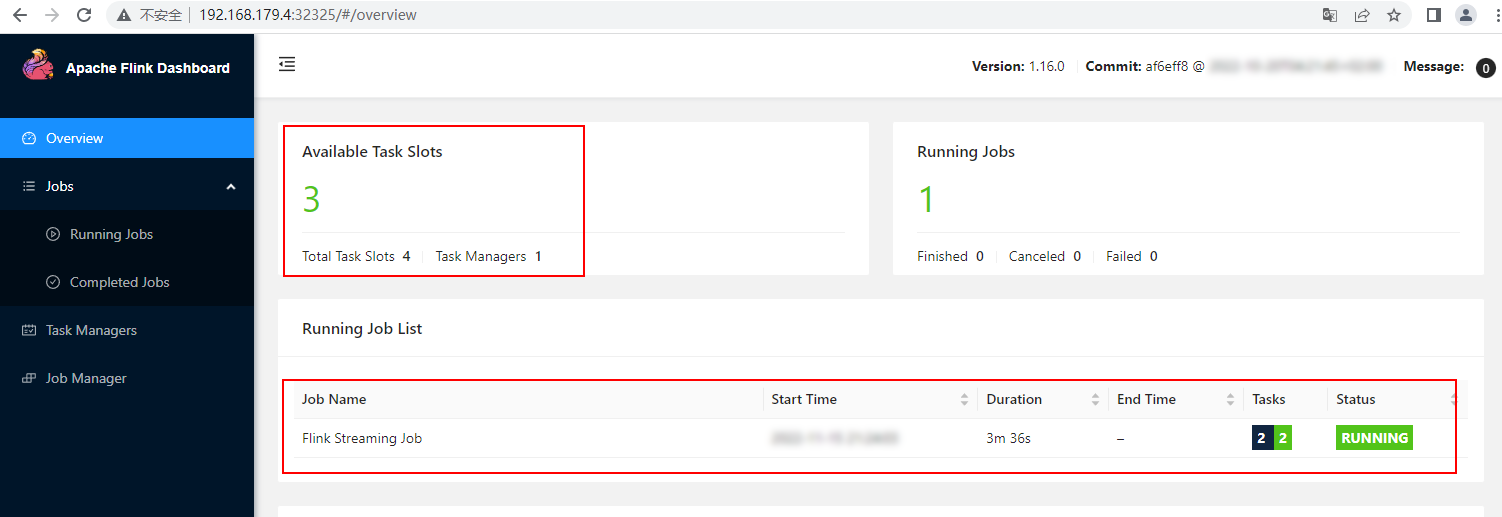
当再次提交Flink任务时,新提交Flink任务同样也会创建新的Flink集群,需要指定的“kubernetes.cluster-id”名称与其他任务不同,例如提交新的Flink任务:
[root@node3 ~]# ./flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster1 \
-Dkubernetes.container.image=www.kubemsb.com/library/myflink:v1 \
-Dkubernetes.rest-service.exposed.type=NodePort\
-Dkubernetes.jobmanager.service-account=flink\
-Dtaskmanager.memory.process.size=1024m \
-Dkubernetes.taskmanager.cpu=1 \
-Dtaskmanager.numberOfTaskSlots=4 \
-c com.mashibing.flinkjava.code.chapter_k8s.WordCount \
local:///opt/flink/usrlib/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
提交新的任务后,同时通过Kubernetes 客户端可以看到不同名称的deployment。

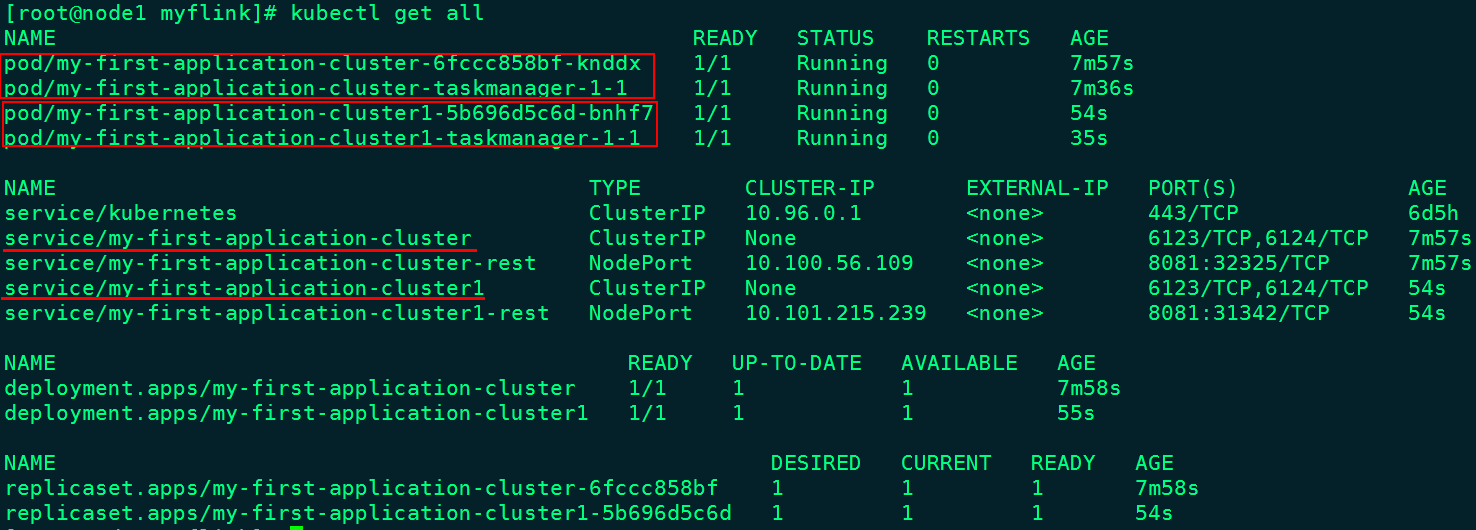
1.8.2.2.4 停止Flink集群¶
可以通过Kubernets命令停止Flink Application集群。命令如下:
#查看Kubernetes中执行的Flink deployment
[root@node1 myflink]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
my-first-application-cluster 1/1 1 1 17m
my-first-application-cluster1 1/1 1 1 9m59s
#停止对应的Flink deployment
[root@node1 ~]# kubectl delete deployment/my-first-application-cluster
[root@node1 ~]# kubectl delete deployment/my-first-application-cluster1
1.9 Kubernetes 基于Docker Runtime¶
从kubernetes 1.24开始,dockershim已经从kubelet中移除(dockershim 是 Kubernetes 的一个组件,主要目的是为了通过 CRI 操作 Docker),但因为历史问题docker却不支持kubernetes主推的CRI(容器运行时接口)标准,所以docker不能再作为kubernetes的容器运行时了,即从kubernetesv1.24开始不再使用docker了,默认使用的容器运行时是containerd。目前containerd比较新,可能存在一些功能不稳定的情况,所以这里我们也可以选择docker作为kubernetes容器运行时。
如果想继续使用docker的话,可以在kubelet和docker之间加上一个中间层cri-docker。cri-docker是一个支持CRI标准的shim(垫片)。一头通过CRI跟kubelet交互,另一头跟docker api交互,从而间接的实现了kubernetes以docker作为容器运行时。
1.9.1 节点划分¶
kubernetes 集群搭建节点分布:
| 节点IP | 节点名称 | Master | Worker |
|---|---|---|---|
| 192.168.179.4 | node1 | ★ | |
| 192.168.179.5 | node2 | ★ | |
| 192.168.179.6 | node3 | ★ | |
| 192.168.179.7 | node4 | ||
| 192.168.179.8 | node5 |
1.9.2 升级内核¶
升级操作系统内核,升级到6.06内核版本。这里所有主机均操作,包括node4,node5节点。
#导入elrepo gpg key
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#安装elrepo YUM源仓库
yum -y install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
#安装kernel-ml版本,ml为长期稳定版本,lt为长期维护版本
yum --enablerepo="elrepo-kernel" -y install kernel-ml.x86_64
#设置grub2默认引导为0
grub2-set-default 0
#重新生成grub2引导文件
grub2-mkconfig -o /boot/grub2/grub.cfg
#更新后,需要重启,使用升级的内核生效。
reboot
#重启后,需要验证内核是否为更新对应的版本
uname -r
6.0.6-1.el7.elrepo.x86_64
1.9.3 配置内核转发及网桥过滤¶
在所有K8S主机配置。添加网桥过滤及内核转发配置文件:
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
加载br_netfilter模块:
#加载br_netfilter模块
modprobe br_netfilter
#查看是否加载
lsmod | grep br_netfilter
加载网桥过滤及内核转发配置文件:
sysctl -p /etc/sysctl.d/k8s.conf
1.9.4 安装ipset及ipvsadm¶
所有主机均需要操作。主要用于实现service转发。
#安装ipset及ipvsadm
yum -y install ipset ipvsadm
配置ipvsadm模块加载方式,添加需要加载的模块
vim /etc/sysconfig/modules/ipvs.modules
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
授权、运行、检查是否加载
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack
1.9.5 关闭SWAP分区¶
修改完成后需要重启操作系统,如不重启,可临时关闭,命令为swapoff -a。永远关闭swap分区,需要重启操作系统。
#永久关闭swap分区 ,在 /etc/fstab中注释掉下面一行
vim /etc/fstab
#/dev/mapper/centos-swap swap swap defaults 0 0
#重启机器
reboot
1.9.6 安装docker¶
所有集群主机均需操作。
获取docker repo文件
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
查看docker可以安装的版本:
yum list docker-ce.x86_64 --showduplicates | sort -r
安装docker:这里指定docker版本为20.10.9版本
yum -y install docker-ce-20.10.9-3.el7
如果安装过程中报错:
Error: Package: 3:docker-ce-20.10.9-3.el7.x86_64 (docker-ce-stable)
Requires: container-selinux >= 2:2.74
Error: Package: docker-ce-rootless-extras-20.10.9-3.el7.x86_64 (docker-ce-stable)
Requires: fuse-overlayfs >= 0.7
Error: Package: docker-ce-rootless-extras-20.10.9-3.el7.x86_64 (docker-ce-stable)
Requires: slirp4netns >= 0.4
Error: Package: containerd.io-1.4.9-3.1.el7.x86_64 (docker-ce-stable)
缺少一些依赖,解决方式:在/etc/yum.repos.d/docker-ce.repo开头追加如下内容:
[centos-extras]
name=Centos extras - $basearch
baseurl=http://mirror.centos.org/centos/7/extras/x86_64
enabled=1
gpgcheck=0
然后执行安装命令:
yum -y install slirp4netns fuse-overlayfs container-selinux
执行完以上之后,再次执行yum -y install docker-ce-20.10.9-3.el7安装docker即可。
设置docker 开机启动,并启动docker:
systemctl enable docker
systemctl start docker
查看docker版本
docker version
修改cgroup方式,并重启docker。
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
#重启docker
systemctl restart docker
1.9.7 cri-docker安装¶
这里需要在全部节点执行cri-docker安装。
1) 下载cri-docker源码
可以从
https://github.com/Mirantis/cri-dockerd/archive/refs/tags/v0.2.6.tar.gz地址下载cri-docker源码,然后使用go进行编译安装。 cri-docker源码下载完成后,上传到Master并解压,改名:
[root@node1 ~]# tar -zxvf ./cri-dockerd-0.2.6.tar.gz
[root@node1 ~]# mv cri-dockerd-0.2.6 cri-dockerd
2) 安装go
[root@node1 ~]# wget https://storage.googleapis.com/golang/getgo/installer_linux
[root@node1 ~]# chmod +x ./installer_linux
[root@node1 ~]# ./installer_linux
[root@node1 ~]# source ~/.bash_profile
[root@node1 ~]# go version
go version go1.19.3 linux/amd64
- 编译安装cri-docker
#进入 cri-dockerd 中,并创建目录bin
[root@node1 ~]# cd cri-dockerd && mkdir bin
#编译,大概等待1分钟
[root@node1 cri-dockerd]# go build -o bin/cri-dockerd
#安装cri-docker,安装-o指定owner -g指定group -m指定指定权限
[root@node1 cri-dockerd]# mkdir -p /usr/local/bin
[root@node1 cri-dockerd]# install -o root -g root -m 0755 bin/cri-dockerd /usr/local/bin/cri-dockerd
#复制服务管理文件至/etc/systemd/system目录中
[root@node1 cri-dockerd]# cp -a packaging/systemd/* /etc/systemd/system
#指定cri-dockerd运行位置
[root@node1 cri-dockerd]# sed -i -e 's,/usr/bin/cri-dockerd,/usr/local/bin/cri-dockerd,' /etc/systemd/system/cri-docker.service
[root@node1 cri-dockerd]# systemctl daemon-reload
#启动服务
[root@node1 cri-dockerd]# systemctl enable cri-docker.service
[root@node1 cri-dockerd]# systemctl enable --now cri-docker
1.9.8 软件版本¶
这里安装Kubernetes版本为1.25.3,在所有主机(node1,node2,node3)安装kubeadm,kubelet,kubectl。
- kubeadm:初始化集群、管理集群等。
- kubelet:用于接收api-server指令,对pod生命周期进行管理。
- kubectl:集群应用命令行管理工具。
1.9.9 准备阿里yum源¶
每台k8s节点vim /etc/yum.repos.d/k8s.repo,写入以下内容:
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
1.9.10 集群软件安装¶
#查看指定版本
yum list kubeadm.x86_64 --showduplicates | sort -r
yum list kubelet.x86_64 --showduplicates | sort -r
yum list kubectl.x86_64 --showduplicates | sort -r
#安装指定版本
yum -y install --setopt=obsoletes=0 kubeadm-1.25.3-0 kubelet-1.25.3-0 kubectl-1.25.3-0
安装过程有有如下错误:
Error: Package: kubelet-1.25.3-0.x86_64 (kubernetes)
Requires: conntrack
解决方式:
wget http://mirrors.aliyun.com/repo/Centos-7.repo -O /etc/yum.repos.d/Centos-7.repo
yum install -y conntrack-tools
1.9.11 配置kubelet¶
为了实现docker使用的cgroup driver与kubelet使用的cgroup的一致性,建议修改如下文件内容。
#vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
设置kubelet为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
systemctl enable kubelet
1.9.12 集群镜像准备¶
只需要在node1 Master节点上执行如下下载镜像命令即可,这里先使用kubeadm查询下镜像。
[root@node1 ~]#kubeadm config images list --kubernetes-version=v1.25.3
registry.k8s.io/kube-apiserver:v1.25.3
registry.k8s.io/kube-controller-manager:v1.25.3
registry.k8s.io/kube-scheduler:v1.25.3
registry.k8s.io/kube-proxy:v1.25.3
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.4-0
registry.k8s.io/coredns/coredns:v1.9.3
编写下载镜像脚本image_download.sh:
#!/bin/bash
images_list='
registry.k8s.io/kube-apiserver:v1.25.3
registry.k8s.io/kube-controller-manager:v1.25.3
registry.k8s.io/kube-scheduler:v1.25.3
registry.k8s.io/kube-proxy:v1.25.3
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.4-0
registry.k8s.io/coredns/coredns:v1.9.3
'
for i in $images_list
do
docker pull $i
done
docker save -o k8s-1-25-3.tar $images_list
以上脚本准备完成之后,执行命令:sh image_download.sh 进行镜像下载
注意:下载时候需要科学上网,否则下载不下来。也可以使用资料中的“k8s-1-25-3.tar”下载好的包。
如果下载不下来,使用资料中打包好的k8s-1-25-3.tar,将镜像导入到docker中¶
docker load -i k8s-1-25-3.tar
1.9.13 集群初始化¶
只需要在Master节点执行如下初始化命令即可。
[root@node1 ~]# kubeadm init --kubernetes-version=v1.25.3 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.179.4 --cri-socket unix:///var/run/cri-dockerd.sock
注意:--apiserver-advertise-address=192.168.179.4 要写当前主机Master IP
初始化过程中报错:
[init] Using Kubernetes version: v1.25.3
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E1102 20:14:29.494424 10976 remote_runtime.go:948] "Status from runtime service
failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"time="2022-11-02T20:14:29+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alp
ha2.RuntimeService", error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
执行如下命令,重启containerd后,再次init 初始化。
[root@node1 ~]# rm -rf /etc/containerd/config.toml
[root@node1 ~]# systemctl restart containerd
初始化完成后,结果如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.179.4:6443 --token tpynmm.7picylv5i83q9ghw \
--discovery-token-ca-cert-hash sha256:2924026774d657b8860fbac4ef7698e90a3811137673af45e533c91e567a1529
1.9.14 集群应用客户端管理集群文件准备¶
参照初始化的内容来执行如下命令:
[root@node1 ~]# mkdir -p $HOME/.kube
[root@node1 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@node1 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@node1 ~]# export KUBECONFIG=/etc/kubernetes/admin.conf
1.9.15 集群网络准备¶
1.9.15.1 calico安装¶
K8s使用calico部署集群网络,安装参考网址:https://projectcalico.docs.tigera.io/about/about-calico。
只需要在Master节点安装即可。
#下载operator资源清单文件
wget https://docs.projectcalico.org/manifests/tigera-operator.yaml --no-check-certificate
#应用资源清单文件,创建operator
kubectl create -f tigera-operator.yaml
#通过自定义资源方式安装
wget https://docs.projectcalico.org/manifests/custom-resources.yaml --no-check-certificate
#修改文件第13行,修改为使用kubeadm init ----pod-network-cidr对应的IP地址段
# vim custom-resources.yaml 【修改和增加以下加粗内容】
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
ipPools:
- blockSize: 26
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
nodeAddressAutodetectionV4:
interface: ens.*
#应用清单文件
kubectl create -f custom-resources.yaml
#监视calico-sysem命名空间中pod运行情况
watch kubectl get pods -n calico-system
[root@node1 ~]# watch kubectl get pods -n calico-system
Every 2.0s: kubectl get pods -n calico-system Thu Nov 3 14:14:30 2022
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-65648cd788-flmk4 1/1 Running 0 2m21s
calico-node-chnd5 1/1 Running 0 2m21s
calico-node-kc5bx 1/1 Running 0 2m21s
calico-node-s2cp5 1/1 Running 0 2m21s
calico-typha-d76595dfb-5z6mg 1/1 Running 0 2m21s
calico-typha-d76595dfb-hgg27 1/1 Running 0 2m19s
#删除 master 上的 taint
[root@node1 ~]# kubectl taint nodes --all node-role.kubernetes.io/master-
taint "node-role.kubernetes.io/master" not found
taint "node-role.kubernetes.io/master" not found
taint "node-role.kubernetes.io/master" not found
#已经全部运行
[root@node1 ~]# kubectl get pods -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-65648cd788-ktjrh 1/1 Running 0 110m
calico-node-dvprv 1/1 Running 0 110m
calico-node-nhzch 1/1 Running 0 110m
calico-node-q44gh 1/1 Running 0 110m
calico-typha-6bc9d76554-4bv77 1/1 Running 0 110m
calico-typha-6bc9d76554-nkzxq 1/1 Running 0 110m
#查看kube-system命名空间中coredns状态,处于Running状态表明联网成功。
[root@node1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-565d847f94-bjtlh 1/1 Running 0 19h
coredns-565d847f94-wlxmf 1/1 Running 0 19h
etcd-node1 1/1 Running 0 19h
kube-apiserver-node1 1/1 Running 0 19h
kube-controller-manager-node1 1/1 Running 0 19h
kube-proxy-bgpz2 1/1 Running 0 19h
kube-proxy-jlltp 1/1 Running 0 19h
kube-proxy-stfrx 1/1 Running 0 19h
kube-scheduler-node1 1/1 Running 0 19h
1.9.15.2 calico客户端安装¶
主要用来验证k8s集群节点网络是否正常。这里只需要在Master节点安装就可以。
#下载二进制文件,注意,这里需要检查calico 服务端的版本,客户端要与服务端版本保持一致,这里没有命令验证calico的版本,所以安装客户端的时候安装最新版本即可。
curl -L https://github.com/projectcalico/calico/releases/download/v3.24.5/calicoctl-linux-amd64 -o calicoctl
#安装calicoctl
mv calicoctl /usr/bin/
#为calicoctl添加可执行权限
chmod +x /usr/bin/calicoctl
#查看添加权限后文件
ls /usr/bin/calicoctl
#查看calicoctl版本
[root@node1 ~]# calicoctl version
Client Version: v3.24.5
Git commit: 83493da01
Cluster Version: v3.24.5
Cluster Type: typha,kdd,k8s,operator,bgp,kubeadm
通过~/.kube/config连接kubernetes集群,查看已运行节点
[root@node1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
node1
1.9.16 集群工作节点添加¶
这里在node2,node3 worker节点上执行命令,将worker节点加入到k8s集群。
[root@node2 ~]# kubeadm join 192.168.179.4:6443 --token tpynmm.7picylv5i83q9ghw \
--discovery-token-ca-cert-hash sha256:2924026774d657b8860fbac4ef7698e90a3811137673af45e533c91e567a1529 --cri-socket unix:///var/run/cri-dockerd.sock
[root@node3 ~]# kubeadm join 192.168.179.4:6443 --token tpynmm.7picylv5i83q9ghw \
--discovery-token-ca-cert-hash sha256:2924026774d657b8860fbac4ef7698e90a3811137673af45e533c91e567a1529 --cri-socket unix:///var/run/cri-dockerd.sock
在master节点上操作,查看网络节点是否添加
[root@node1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
node1
node2
node3
1.9.17 验证集群可用性¶
使用命令查看所有的节点:
[root@node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 20h v1.25.3
node2 Ready <none> 20h v1.25.3
node3 Ready <none> 20h v1.25.3
查看集群健康情况:
[root@node1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
etcd-0 Healthy {"health":"true","reason":""}
scheduler Healthy ok
controller-manager Healthy ok
查看kubernetes集群pod运行情况:
[root@node1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-565d847f94-bjtlh 1/1 Running 0 20h
coredns-565d847f94-wlxmf 1/1 Running 0 20h
etcd-node1 1/1 Running 0 20h
kube-apiserver-node1 1/1 Running 0 20h
kube-controller-manager-node1 1/1 Running 0 20h
kube-proxy-bgpz2 1/1 Running 1 20h
kube-proxy-jlltp 1/1 Running 1 20h
kube-proxy-stfrx 1/1 Running 0 20h
kube-scheduler-node1 1/1 Running 0 20h
查看集群信息:
[root@node1 ~]# kubectl cluster-info
Kubernetes control plane is running at https://192.168.179.4:6443
CoreDNS is running at https://192.168.179.4:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
1.9.18 K8s集群其他一些配置¶
当在Worker节点上执行kubectl命令管理时会报如下错误:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
只要把master上的管理文件/etc/kubernetes/admin.conf拷贝到Worker节点的$HOME/.kube/config就可以让Worker节点也可以实现kubectl命令管理。
#在Worker节点创建.kube目录
[root@node2 ~]# mkdir /root/.kube
[root@node3 ~]# mkdir /root/.kube
#在master节点做如下操作
[root@node1 ~]# scp /etc/kubernetes/admin.conf node2:/root/.kube/config
[root@node1 ~]# scp /etc/kubernetes/admin.conf node3:/root/.kube/config
#在worker 节点验证
[root@node2 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 24h v1.25.3
node2 Ready <none> 24h v1.25.3
node3 Ready <none> 24h v1.25.3
[root@node3 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 24h v1.25.3
node2 Ready <none> 24h v1.25.3
node3 Ready <none> 24h v1.25.3
此外,无论在Master节点还是Worker节点使用kubenetes 命令时,默认不能自动补全,例如:kubectl describe 命令中describe不能自动补全,使用非常不方便,那么这里配置命令自动补全功能。
在所有的kubernetes节点上安装bash-completion并source执行,同时配置下开机自动source,每次开机能自动补全命令。
#安装bash-completion 并 source
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
kubectl completion bash > ~/.kube/completion.bash.inc
source '/root/.kube/completion.bash.inc'
#实现用户登录主机自动source ,自动使用命令补全
vim ~/.bash_profile 【加入加粗这一句】
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
source '/root/.kube/completion.bash.inc'
PATH=$PATH:$HOME/bin
export PATH
默认K8S我们只要设置了systemctl enable kubelet 后,会在开机自动启动K8S集群,如果想要停止kubernetes集群,我们可以通过systemctl stop kubelet 命令停止集群,但是必须先将节点上的docker停止,命令如下:
1.9.19 K8s集群启停¶
systemctl stop docker
然后再停止k8s集群:
systemctl stop kubelet
启动Kubernetes集群步骤如下:
# 先启动docker
systemctl start docker
# 再启动kubelet
systemctl start kubelet